Handbücher abschaffen! Vom Dokument zur Wissensdatenbank
Zugehörige Leistung: Self-Service-Lösungen
Klassischerweise wird Technische Dokumentation als Handbuch erstellt – für bestimmte Zielgruppen und Produktvarianten. Redaktionssysteme unterstützen Redakteure, Textmodule mit Metadaten zu versehen, sodass sie korrekt zu Handbüchern zusammengestellt werden können. Mit Industrie 4.0 und der stärkeren Modularisierung von Informationen ist handbuchbasierte Dokumentation jedoch nicht zukunftssicher.
Denn in einer Welt der individualisierten Produkte müssen technische Informationen entsprechend der Konfiguration und passend zum Anwendungskontext bereitgestellt werden. Eine solche Bereitstellung kann semantische Software realisieren, die strukturierte Dokumentationsdaten auswertet und dynamisch ausliefert.
1. Neue Herausforderungen für die Dokumentation
Technische Produkte werden immer komplexer. Zudem werden sie in immer zahlreicheren Varianten ausgeliefert. Aber jede Produktvariante benötigt ihre passende Dokumentation, so fordert es die Gesetzgebung. Das bedeutet, dass Technische Redakteure Anleitungen für mehrere Varianten, verschiedene Zielgruppen und verschiedene Medien produzieren müssen, z.B. als mobile Variante für das Smartphone.
Zudem haben sich unsere Lesegewohnheiten geändert. Selten lesen wir noch ganze Handbücher. Heutzutage konsumieren wir Informationen häppchenweise. Gezielt suchen wir nach Informationen, die wir gerade benötigen und die zu der Handlung passen, die wir gerade ausführen. Selbstverständlich erwarten wir, dass die Informationshäppchen einfach zu finden, passgenau und aktuell sind. Wir verwenden Suchfunktionen und zielgruppengerechte Filter. Wir teilen die Informationen in sozialen Netzen oder hinterlassen ein Feedback.
Technische Dokumentation für Maschinen und Anlagen beschreibt klassischerweise jedoch immer noch geschlossene technische Systeme mit fest definierten Funktionen und Komponenten. Die Dokumentation zu den gefertigten Produkten geht ebenfalls von einem fest vorgegebenen Produkt aus. Dokumentation im Zeitalter von Industrie 4.0 und cyber-physischen Systemen, deren Komponenten variabel interagieren, muss sich jedoch weg von Systemen hin zu Komponenten orientieren. Sie muss berücksichtigen, wie die Komponenten in das Gesamtsystem integriert sind, welche Funktionen und Dienste die Komponente bietet. Auch muss sie Anwendungen wie die Bedienung und die Wartung von Komponenten unterstützen. Da die genaue Ausprägung des Systems nicht bei Fertigung der Komponente feststeht, wird Dokumentation zur Komponentendokumentation.
2. Konsequenzen für die Dokumentation
All diese neuen Herausforderungen kann die klassische, handbuchorientierte Dokumentation nicht erfüllen. Ist die Dokumentation damit tot? Nein, nur die handbuchartige Anordnung und Auslieferung von Dokumentation. Denn natürlich wird jedes Produkt weiterhin von Informationen zu Anwendung, Wartung und Reparatur begleitet.
Um jedoch auch im Zeitalter von Industrie 4.0 zielgruppengerechte Dokumentation auszuliefern, muss sich die Technische Dokumentation weiterentwickeln.
2.1 Modularisiert schreiben und mit Metadaten klassifizieren
Dokumentation, die sich an Komponenten statt an vollständigen Systemen orientiert, muss modular erstellt werden. Modulare Dokumentation ist jetzt schon Standard in vielen technischen Redaktionen und wird durch Standard-XML-Architekturen wie DITA oder PI-Mod sowie unternehmensspezifische XML-Architekturen in XML-Redaktionssystemen unterstützt. Die Granularität der Module ist derzeit sehr unterschiedlich. Sie reicht von vollständigen Kapiteln bis hin zu einzelnen Sätzen. Für eine semantische Erschließung und dynamische Zusammenstellung von Informationshäppchen ist eine Modulgröße im Kapitelbereich voraussichtlich nicht praxistauglich, sie wird sich verringern.
Die semantische Erschließung von Dokumentation erfordert außerdem Metadaten. Metadaten verwenden wir als technische Redakteure schon lange. Sie dienen uns dazu, Textmodule für spezielle Zielgruppen, Medien oder Produktvarianten auszuzeichnen. Mit Industrie 4.0 werden die Komponenteninformationen wichtiger. Die Komponentenhierarchie muss daher Teil der Metadaten für Dokumentation werden. Moderne XML-Redaktionssysteme unterstützen diese Art der Klassifizierung bereits. Beispiele sind die Taxonomiefunktionen in Schema ST4 und in Docufy Cosima.
Aber auch freie XML-Architekturen wie DITA unterstützen die Anwendung von Taxonomien und Ontologien auf technische Inhalte. Das folgende Bildschirmfoto zeigt ein Textmodul inoXygen (einen so genannten DITA-Topic) mit Metadaten für Produktkomponente und Informationsart. DITA bietet zudem semantische Elemente sowohl für den Maschinen- und Anlagenbau als auch die Software-Industrie. Das ermöglicht die gezielte Abfrage und Zusammenstellung durch semantische Applikationen.
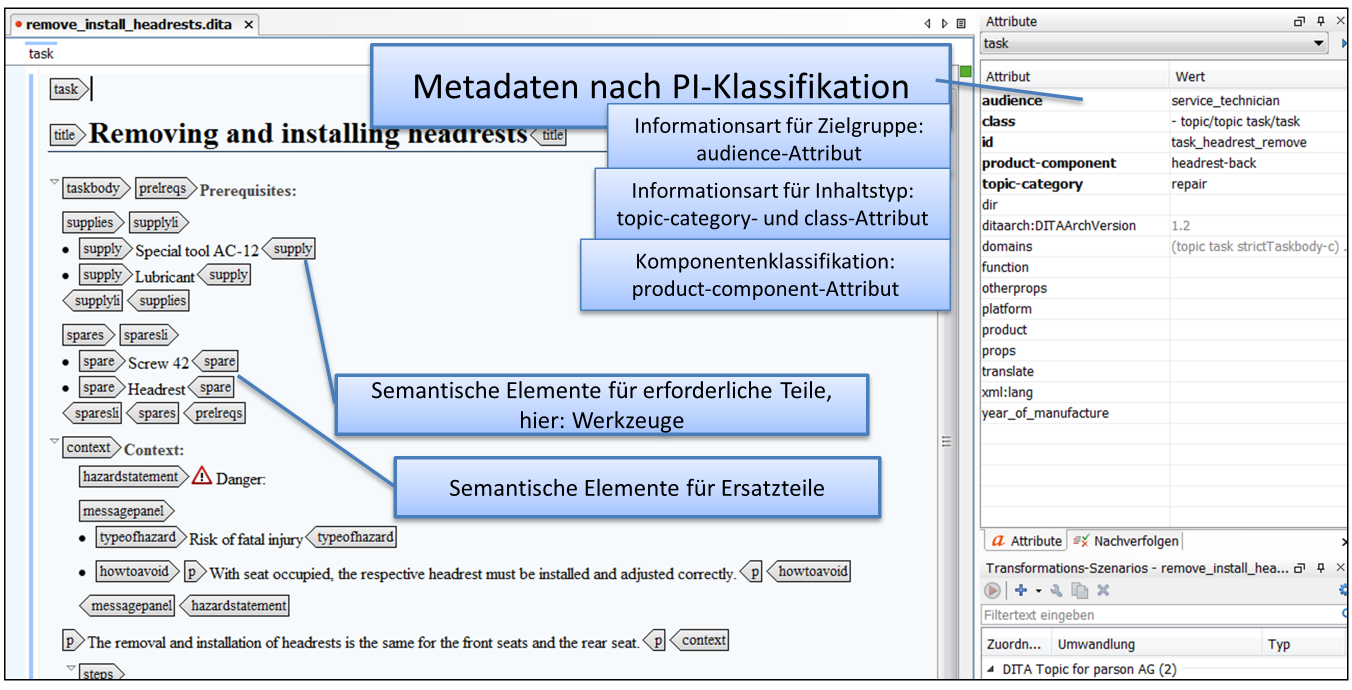
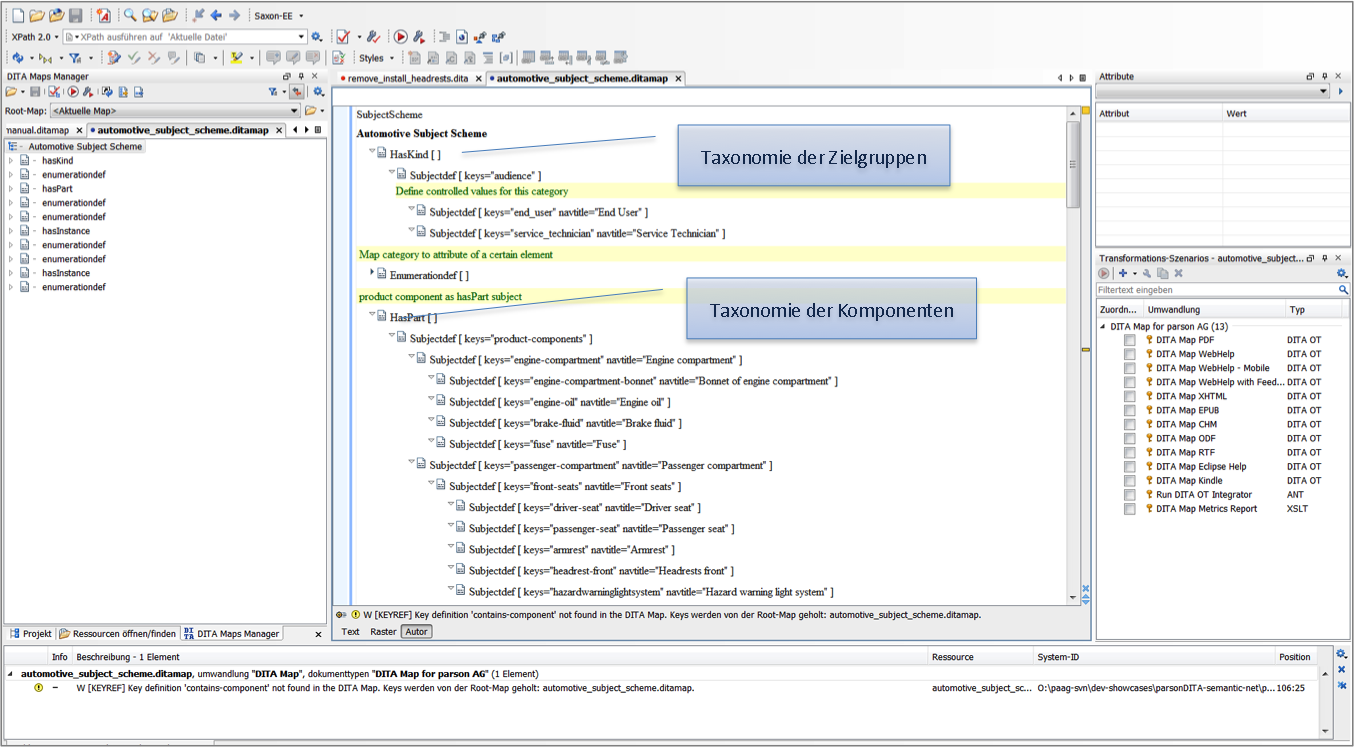
Das semantische Modell, das der Klassifizierung der Inhalte zugrundeliegt, kann in DITA in Form von so genannten Subject-Scheme-Maps definiert werden. DITA bietet dabei nicht nur die Möglichkeit, eine hierarchische Taxonomie aufzubauen, sondern hat auch Elemente, um die Art der Beziehung zwischen den Konzepten zu definieren. In unserem Beispiel aus der Abbildung verwenden wir u.a. die HasPart-Beziehung für die Komponenten-Taxonomie.
Für die Definition von Beziehungen zwischen Konzepten, in unserem Beispiel die Produktzugehörigkeit der Komponenten, stellt DITA verschiedene Mechanismen zur Verfügung: Classification-Maps und Subject-Relation-Tables.
2.2 Formate und Terminologie vereinheitlichen
Aus den Abbildungen im vorangegangen Abschnitt ist ersichtlich, dass die herkömmlichen Redaktionswerkzeuge nur mit hierarchischen Strukturen umgehen bzw. jeweils nur eine von vielen denkbaren Beziehungen in einer Hierarchie darstellen können. Eine echte Pflege eines vernetzten Modells ist nicht möglich. Zudem werden viele Einträge, die als Metadaten bei der Dokumentation verwendet werden wie bspw. Produktdateninformationen in externen Systemen erstellt und verwaltet. Sie stehen damit nicht ohne weiteres zur Auszeichnung für die Dokumentation zur Verfügung. Der Einsatz einer semantischen Software zur Integration von Metadaten aus unterschiedlichen Systemen kann in diesem Punkt Abhilfe schaffen. Mit einer solchen Software ist dann auch die Kontrolle der Terminologie und des verwendeten Vokabulars möglich. Damit kann garantiert werden, dass nur Auswahlwerte für die Vergabe von Metadaten verwendet werden und keine Probleme mit unterschiedlichen Schreibweisen oder Benennungen entstehen. Durch die Integration können verschiedene Arten von Metadaten miteinander verbunden werden:
- Metadaten, die sich direkt auf die Informationen beziehen wie bspw. der Freigabestatus oder das Datum der letzten Änderung und die direkt in der Redaktionsumgebung „produziert“ werden
- Metadaten zur Art der Informationen wie die Eignung des Inhalts für eine bestimmte Zielgruppe, die Verbindung mit einer (Produkt-)Komponente oder einem Werkzeug
- Metadaten zum Aufbau verschiedener Produktvarianten aus Komponenten (Produkt-Taxonomie)
Die Flexibilität einer solchen Software ermöglicht zudem eine einfache Erweiterung des Modells und die Integration von Inhalten, die mit unterschiedlichen Formaten ausgezeichnet sind.
Die folgenden beiden Abbildungen zeigen die die hierarchische Struktur des Metadatenschemas und die tatsächliche Verwendung zur Beschreibung von Inhaltsbausteinen.
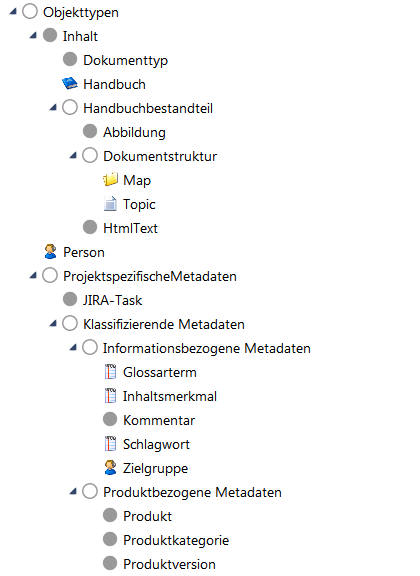
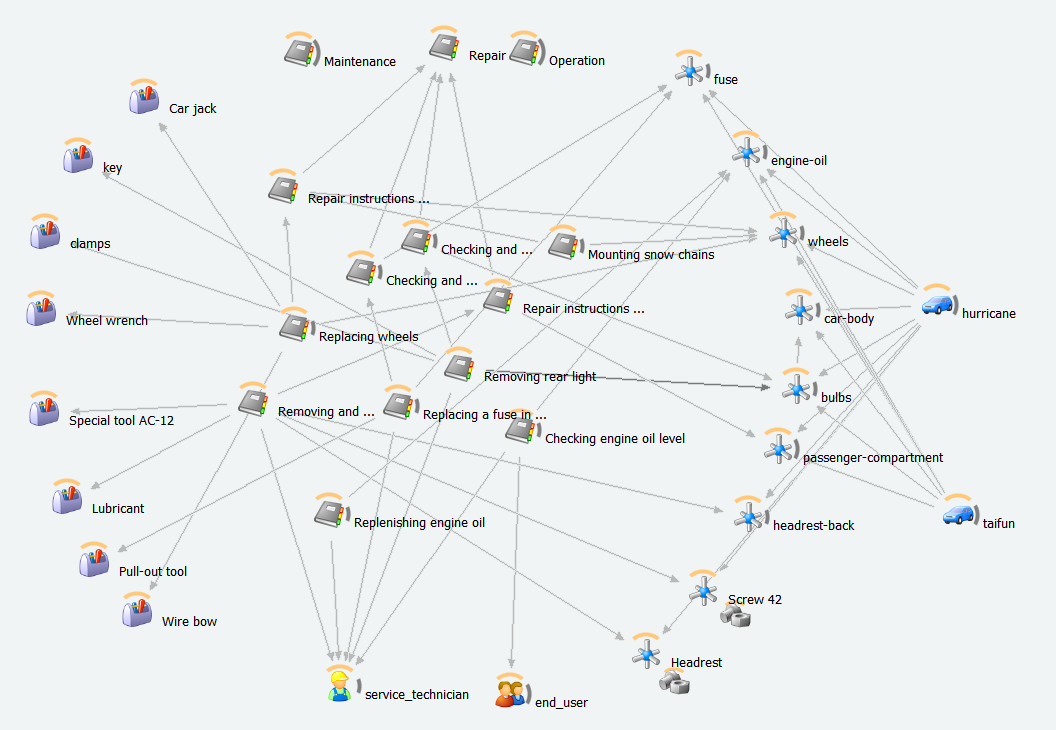
Mit Hilfe der Vernetzung der Inhalte mit Zielgruppen , Komponenten und Werkzeugen die aus Produkt- oder Service-Managementsystemen stammen, können damit dynamisch Inhalte und Publikationen generiert werden. Zudem können die Metadaten für intelligente Such- und Filterfunktionen für die Inhalte verwendet werden.
3. Wissen statt Dokumente liefern
3.1 Content Delivery
Bislang haben Technische Redakteure Metadaten vor allem für die Zusammenstellung von statischen Dokumenten verwendet. Nach dem Filtern und Zusammenstellen der Module waren die Metadaten nicht länger vonnöten und wurden daher nicht mit ausgeliefert.
Das wird sich ändern. Dokumentation, die im Kontext eines individualisierten Produkts angewendet werden soll, muss die dynamische Zusammenstellung und das Filtern von Inhalten unterstützen. Das bedeutet, dass die Metadaten zusammen mit der modularen Dokumentation ausgeliefert werden müssen. Nur so können sich Anwender oder Applikationen aus einer Wissensdatenbank mit Dokumentationsmodulen genau die Informationshäppchen rauszusuchen, die gerade gebraucht werden.
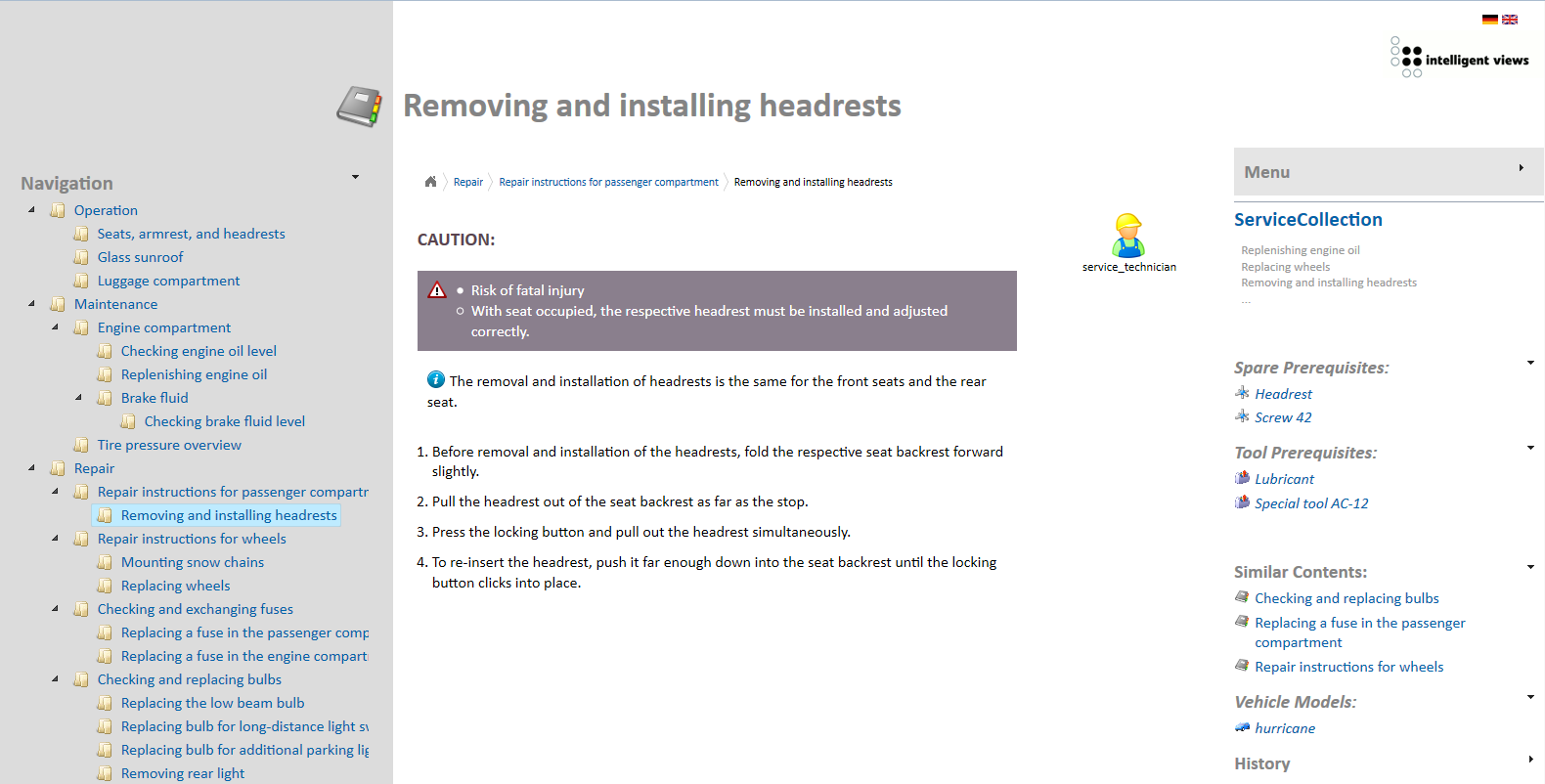
Für die Lieferung von Dokumentationsinhalten einschließlich Metadaten in Wissensdatenbanken, Portalen oder Dokumentationsanwendungen prägt sich derzeit der Begriff Content Delivery. Bereits heute sind einige Lösungen für Content-Delivery-Portale auf dem Markt. Content-Delivery-Portale bieten eine webbasierte Oberfläche für die Präsentation und das inhaltliche Erschließen umfangreicher Informationen und Dokumente. Die Inhalte des Portals sind mit Metadaten angereichert, um das zielgruppen- und kontextabhängige Filtern von Informationen und semantische Suchabfragen zu unterstützen. Die Inhalte selbst werden nicht im Portal erstellt, sondern kommen aus einem oder verschiedenen Autorensystemen. Content-Delivery-Portale werden von verschiedenen Anbietern entwickelt oder bereits angeboten. Dabei kann man zwischen verschiedenen Kategorien unterscheiden:
- Portal (vorrangig) für Inhalte des Redaktionssystems. Beispiel: Docufy TopicPilot
- Systemunabhängige Portale für Inhalte im standardisierten XML-Format. Beispiele für DITA-Content-Delivery-Portale sindDITAweb oder FluidTopics
- Enterprise-Content-Portal für strukturierte und unstrukturierte Inhalte aus mehreren Systemen, z.B. auf Basis einer semantischen Software. Beispiel ist das Semantic Content Delivery Portal (SECONDS) von intelligent views.
Fazit
Statt wie in der Vergangenheit die Inhalte statisch und linear zu präsentieren, werden sie jetzt dynamisch und flexibel zur Verfügung gestellt und für verschiedene Medienformen veröffentlicht.
Voraussetzungen dafür sind:
- Eine verbindliche und systemübergreifend einheitliche Klassifikation der Dokumentationsinhalte
- Dokumentation, die nicht nur modular erstellt, sondern auch modular und mit Metadaten angereichert ausgeliefert wird.
- Technische Lösungen für die Erschließung der klassifizierten Dokumentation und die Präsentation in einem Content-Delivery-Portal oder einer Dokumentationsanwendung. Semantische Technologien bilden hier die ideale Grundlage.
Neuen Kommentar hinzufügen