Erst die Metadaten, dann der Inhalt. Wenn Metadaten das Redaktionssystem steuern
Zugehörige Leistungen: Metadatenmodelle für die Technische Dokumentation und Redaktionssysteme und CCMS
Metadaten haben zu einem Paradigmenwechseln in der technischen Kommunikation geführt. Nicht mehr das Redaktionssystem steht am Anfang aller Prozesse, sondern die Metadaten.
Dieser Artikel beruht auf dem gleichnamigen Vortrag von Ulrike Parson und Dr. Achim Steinacker bei der tekom-Jahrestagung 2021.
Aktuelle Prozesse in der Technischen Redaktion
Viele Technische Redaktionen arbeiten mit einem Redaktionssystem, in dem sie Inhalte bearbeiten und mithilfe von Workflows prüfen, übersetzen und freigeben. Wenn das Redaktionssystem über entsprechende Schnittstellen verfügt, kann die Redaktion auch Informationen aus externen Systemen wie einem Produktinformationsmanagement oder einer Ersatzteilverwaltung nutzen.
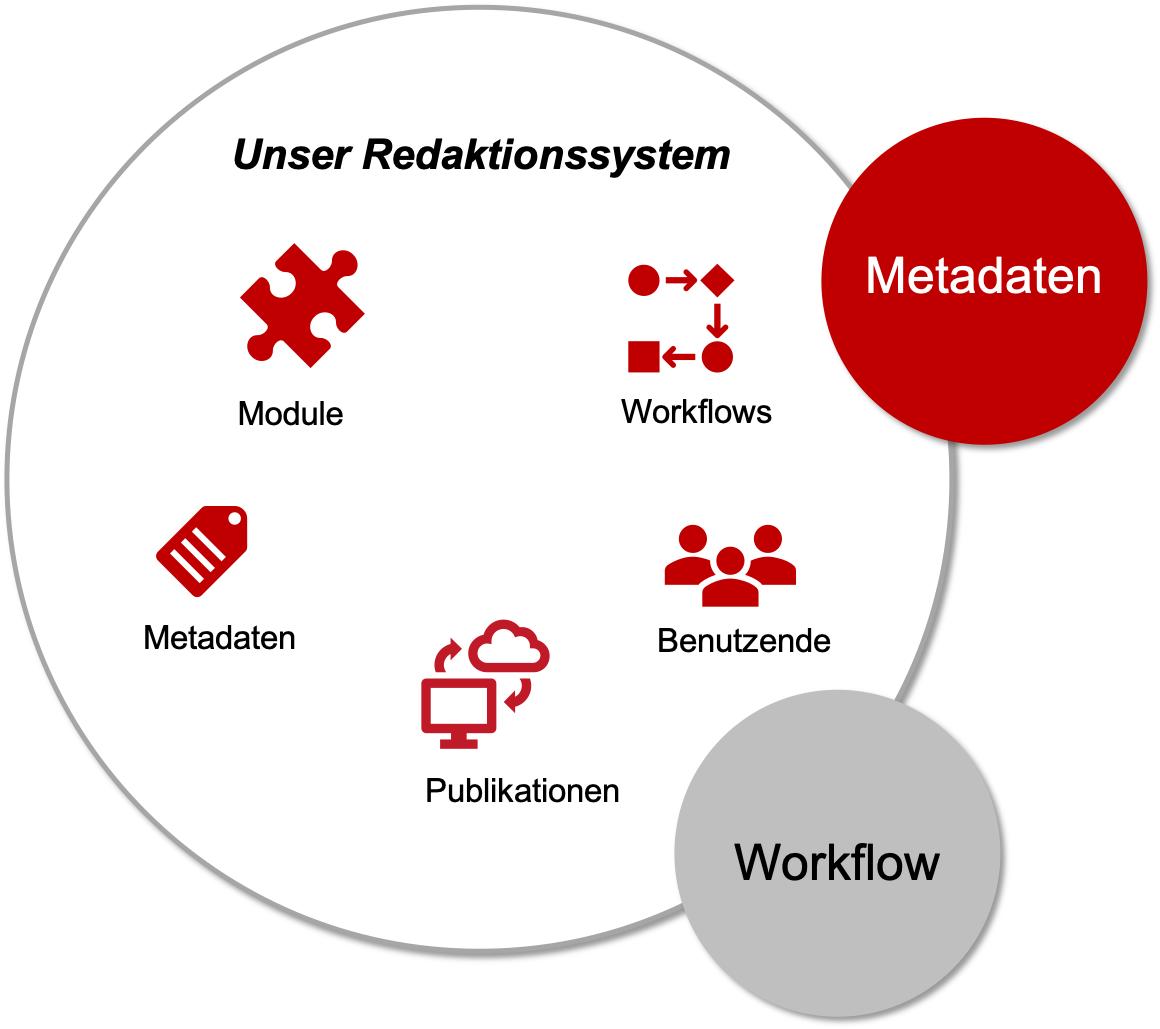
Im Redaktionssystem werden neben den Inhalten auch Metadaten verwaltet, die von der Redaktion zugewiesen oder vom System automatisch gesetzt werden. Die Redaktion arbeitet vorrangig mit Metadaten für das Variantenmanagement, um Dokumentation für verschiedene Produktvarianten, Plattformen, Zielgruppen oder Medien aus einer Quelle zu produzieren. Daneben gibt es administrative Metadaten, die an die Workflows gebunden sind, beispielsweise Erstelldatum, Freigabedatum, Übersetzungsstatus, Gültigkeit oder Autor:in.

Der klassische Redaktions- und Übersetzungsworkflow kann daher auf drei Phasen verallgemeinert werden:
- Inhalte erstellen und bearbeiten
- Inhalte übersetzen
- Dokumente publizieren

Für die Nutzung werden die publizierten Dokumente ausgeliefert, z.B. als kontextsensitive Hilfe in Software, als PDF-Dokumente auf Websites oder als iiRDS-Paket in Content-Delivery-Portale.
Neue Anforderungen durch die Digitalisierung
Durch die zunehmende Digitalisierung ergeben sich neue Nutzungsszenarien für Informationen, in denen auch Inhalte aus der technischen Dokumentation eine Rolle spielen.
Szenario 1: Chatbots
Chatbots oder Sprachassistenten werden zunehmend wichtiger. Nutzer:innen wollen Fragen stellen und schnell eine passende Lösung für ihr Problem finden. Chatbots sind darauf spezialisiert, bei konkreten Fragestellungen zu helfen und Handlungsanweisungen bereitzustellen.
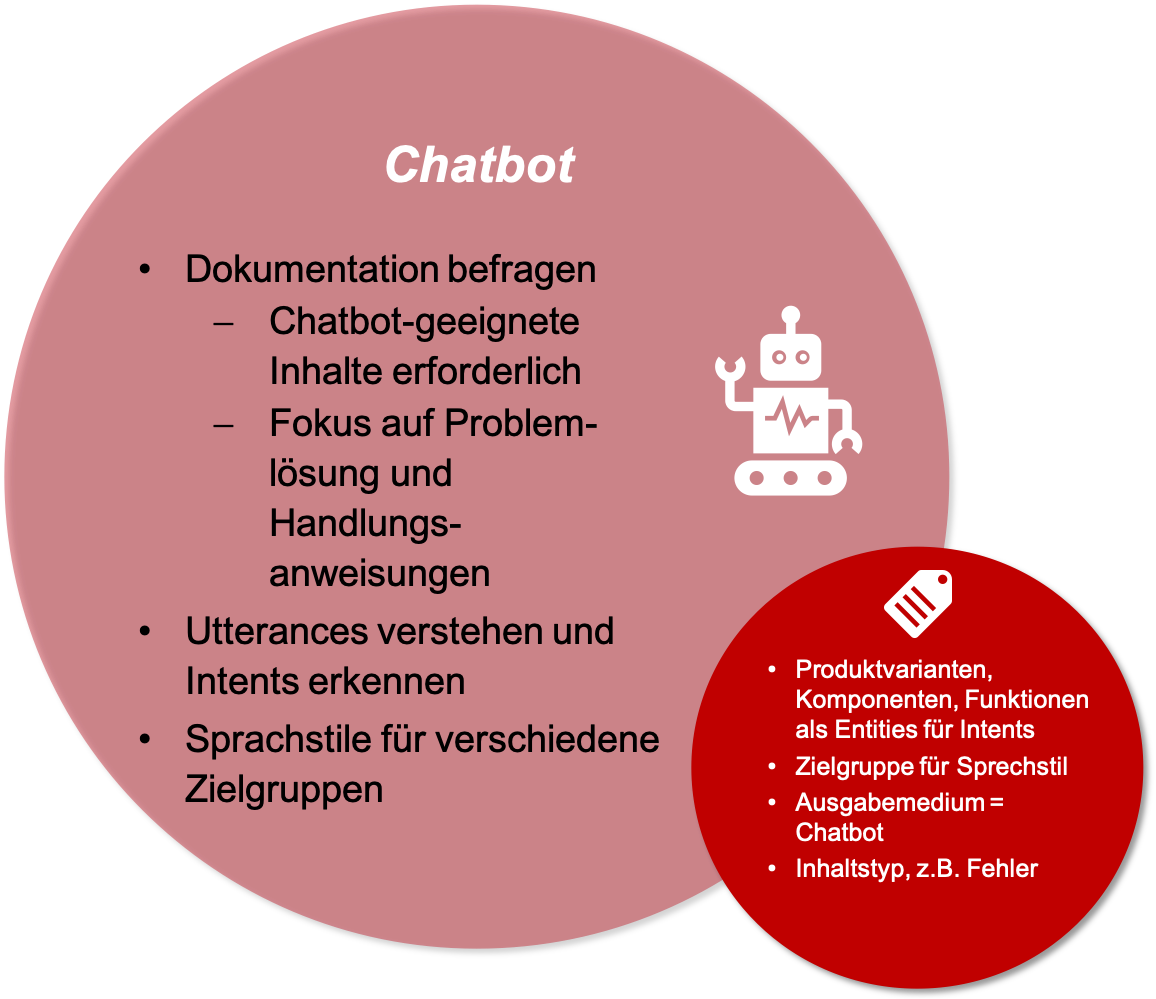
Um die richtigen Antworten finden, benötigen auch Chatbot-Implementierungen Metadaten. Sie müssen in der Lage sein zu erkennen, um welche Produktvariante es sich handelt, bei welcher Komponente oder welcher Funktion ein Fehler auftritt und wer gerade die Frage stellt. Letzteres kann wichtig sein, um den richtigen Sprachstil zu wählen. Außerdem muss klar sein, welche Inhalte mit der Antwort ausgeliefert werden sollen, z.B. ob es eher um eine konkrete Problemlösung geht oder allgemeine Hintergrundinformationen.
Szenario 2: Digitaler Zwilling
Der digitale Zwilling ist eine elektronische Abbildung aller Komponenten, Dienste und Schnittstellen eines technischen Systems. Zu einem System können Komponenten von mehreren Herstellern gehören. Der digitale Zwilling enthält auch Informationen aus der technischen Dokumentation.
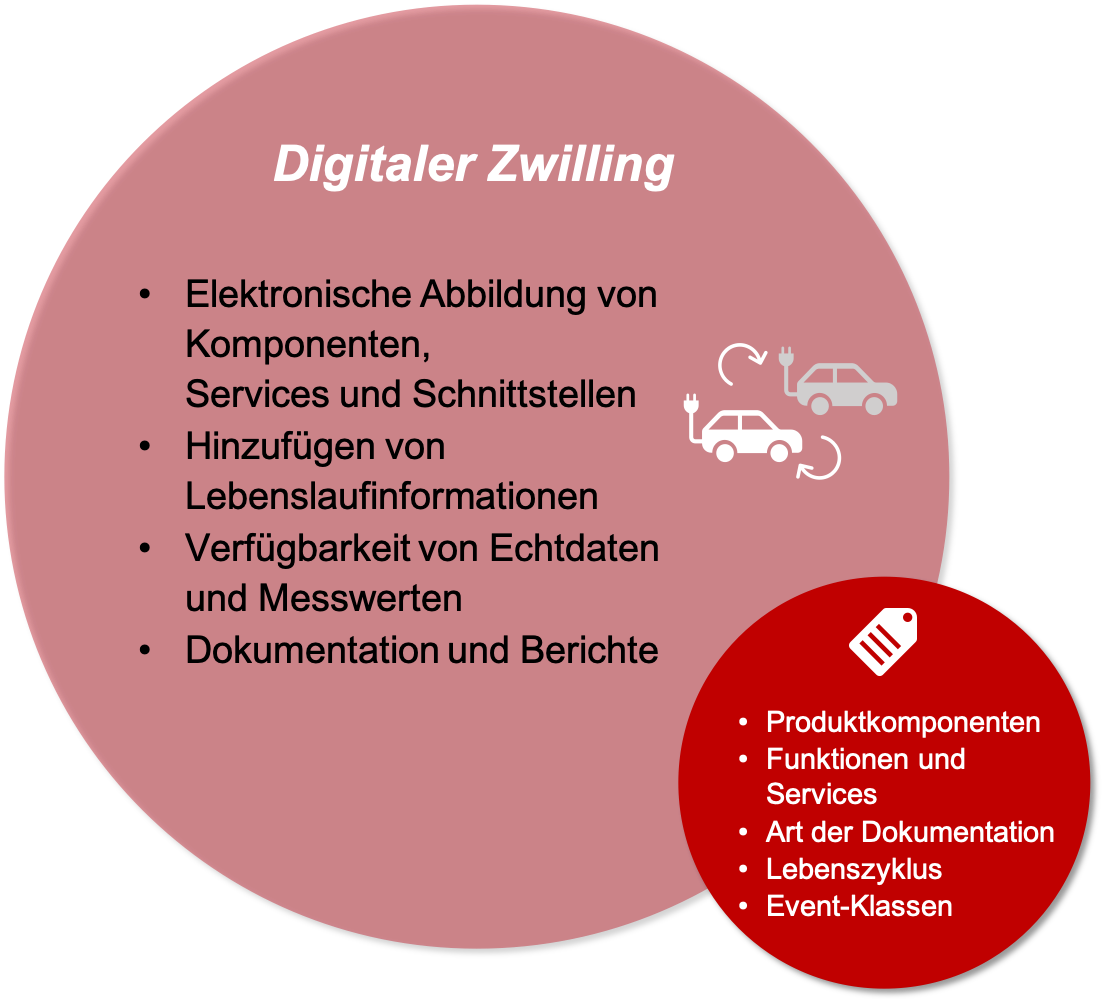
Im Laufe des Lebens eines technischen Systems kommen weitere Informationen hinzu: Teile werden ersetzt, Schnittstellen hinzugefügt, Wartungsarbeiten vorgenommen oder Firmware aktualisiert. All diese Lebenslaufinformationen werden dem digitalen Zwilling hinzugefügt.
Wenn jemand in einem digitalen Zwilling nach Informationen sucht, braucht er oder sie ebenfalls Metadaten. Zum Beispiel, um nach spezifischen Komponenten zu suchen, die passenden Anleitungen zu einem Fehler zu finden oder Instruktionen für eine anstehende Wartung zu erhalten.
Szenario 3: Self-Service-Portal
Self-Service-Portale werden für Hersteller immer wichtiger. Hier finden die Anwender:innen, aber auch Servicetechniker und Entwickler, Hilfe und Informationen zum Produkt, zum Beispiel Handlungsanweisungen, Problemlösungen oder technische Daten.
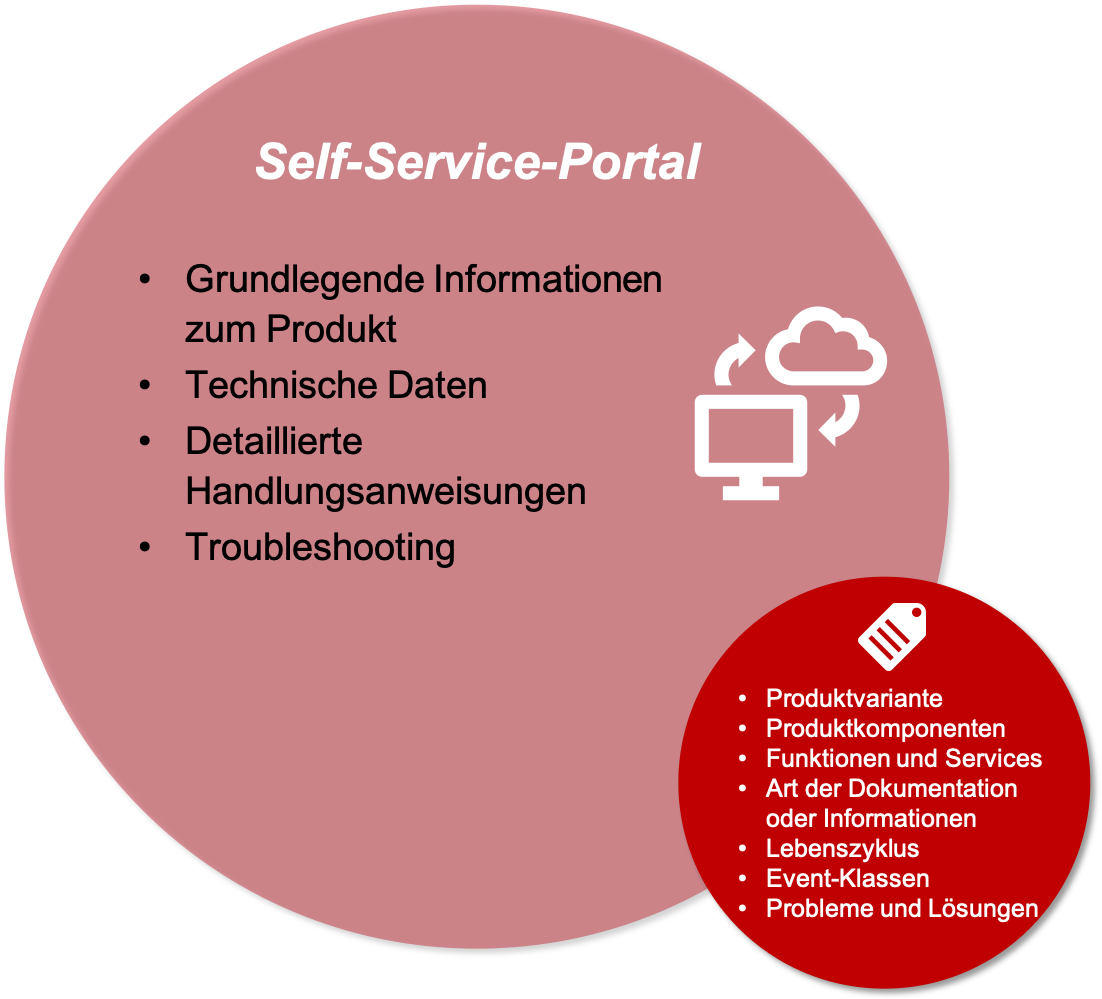
In einem Self-Service-Portal spielen Metadaten eine besonders wichtige Rolle, denn hier werden in der Regel Informationen aus verschiedenen Quellen zusammengeführt. Es wird nach Produktvariante, Produktfunktion oder Zielgruppe gefiltert und nach Problemlösungen gesucht. Dafür werden ähnliche Metadaten wie in den vorherigen Szenarien benötigt.
Szenario 4: Produktkonfigurator
Viele Hersteller bieten Produktkonfiguratoren an. Die Kund:innen nutzen sie, um sich ihr Wunschprodukt aus bestimmten Modulen und mit bestimmten Funktionalitäten und Produktmerkmalen zusammenzustellen. Produktkonfiguratoren finden man bei Consumer-Produkten, aber auch im industriellen Umfeld. Die technische Kommunikation spielt auch hier eine Rolle, denn für die zusammengestellten Produkte muss es natürlich auch eine passgenaue Dokumentation geben. Zudem können Dokumente wie Datenblätter und Funktionsbeschreibungen die Kaufentscheidung unterstützen. Auch ein Produktkonfigurator benötigt Metadaten, denn er muss die Zusammenhänge zwischen Komponenten, Modulen, Funktionalitäten, Ausstattungsmerkmalen, Bestelloptionen, Lizenzen, Preisen und Produktvarianten kennen. Zudem muss ggf. eine Verbindung zu passenden Dokumentationsinhalten hergestellt werden.
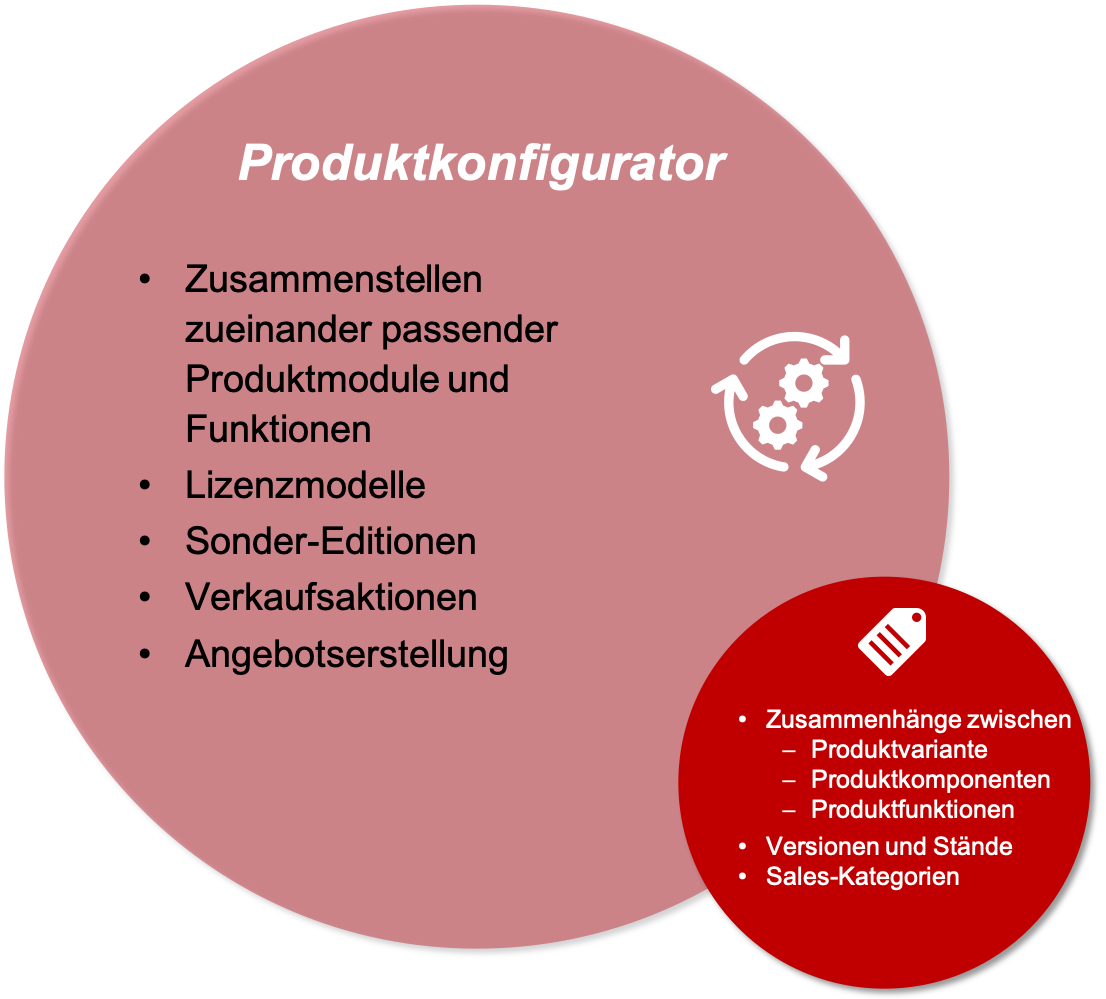
All diese Metadaten auch in der Technischen Redaktion?
Es gibt also eine ganze Reihe von Anwendungsfällen, die Metadaten erfordern. Einige Arten von Metadaten wie Produktdaten, Zielgruppe und Informationsarten tauchen in mehreren der genannten Szenarien auf.
Was bedeutet das für die Technische Redaktion? Müssen alle diese Metadaten auch im Redaktionssystem vorhanden sein, um die passenden Inhalte für jedes dieser Szenarien liefern zu können? Dabei stellen sich folgende Fragen:
- Kennt die Technische Redaktion überhaupt alle Nutzungsszenarien ihrer Inhalte und die benötigten Metadaten? Weiß sie, welches Nutzungsszenario welche Produkteigenschaften betrifft und welche Parameter die Situation beschreiben, damit sie auch die richtige Dokumentation dafür zusammenstellen kann?
- Wer definiert eigentlich originär welche Metadaten? Wer sorgt für die Aktualisierung und Synchronisation von Metadaten im Unternehmen?
- Was passiert, wenn sich Produkteigenschaften und Anwendungsfälle ändern?
- Soll die Technische Redaktion all diese Metadaten manuell zuweisen? Beim Chatbot-Szenario, das ja sehr feingranulare Inhalte benötigt, wäre das ggf. auf Satzebene notwendig und das wäre sehr aufwändig.
- Was passiert, wenn die Information für ein neues Nutzungsszenario publiziert werden sollen, z.B. weil es nun einen Chatbot für den Service gibt? Soll die Technische Redaktion dann alle Bestandsinhalte nachträglich mit Metadaten verschlagworten?
- Welches Metadatenmodell kann die Technische Redaktion für die Dokumentation oder für die Produkte nutzen? Gibt es hier etablierte Standards, an denen man sich orientieren kann, Vokabularien, die man übernehmen und erweitern kann?
Anwendungsübergreifendes Informationsmodell schaffen
Das Redaktionssystem eignet sich nicht dafür, um alle benötigten Metadaten zu verwalten und zu pflegen. Die administrativen Metadaten für die technische Dokumentation und die variantengebenden Merkmale sind im Redaktionssystem richtig aufgehoben. Aber für allgemeine Produktmodelle, den digitalen Zwilling und vernetzte Informationsmodelle ist das Redaktionssystem der falsche Platz.
Da sich außerdem die benötigten Metadaten für verschiedene Anwendungsszenarien überschneiden, besteht der richtige Ansatz darin, die Metadaten aus den individuellen Anwendungen herausziehen, sie zusammenfassen und in einem anwendungsübergreifenden Informationsmodell zu verwalten.
iiRDS als Ausgangspunkt
Mit iiRDS kann man Metadaten abbilden und verwalten, die für die technische Kommunikation relevant sind. iiRDS liefert Anknüpfungspunkte für andere Metadaten und Modelle, zum Beispiel für den digitalen Zwilling einer Maschine mit Informationen zu Komponenten, Funktionen und Ereignissen. Damit kann iiRDS als Ausgangspunkt oder Bestandteil eines größeren Informationsmodells verwendet werden.
Bei Verwendung eines anwendungsübergreifenden Informationsmodells müssen die Metadaten nicht mehr getrennt für die einzelnen Nutzungsszenarien definiert und verwaltet werden. In dem Informationsmodell können verschiedene Arten von Metadaten zusammengeführt werden, u.a. Produktmerkmale, Produktfunktionen, technische Daten, Informationsarten, Zielgruppen u.a.
Digitaler Informationszwilling (Digital Information Twin)
Angelehnt an den digitalen Zwilling nennen wir dieses Informationsmodell den digitalen Informationszwilling (digital information twin). Um mit einem solchen Informationszwilling Redaktionsprozesse für Produkte zu steuern, sind folgende Informationen wichtig:
- Informationen aus dem digitalen Zwilling des Produkts, u.a. Komponenten, Funktionen und Produktmerkmale
- Metadaten für technische Dokumentation, u.a. Topic-Arten
- Ein generisches Informationsmodell für die Inhalte der technischen Dokumentation
- Wissen über die bestehenden Informationseinheiten im Redaktionssystem
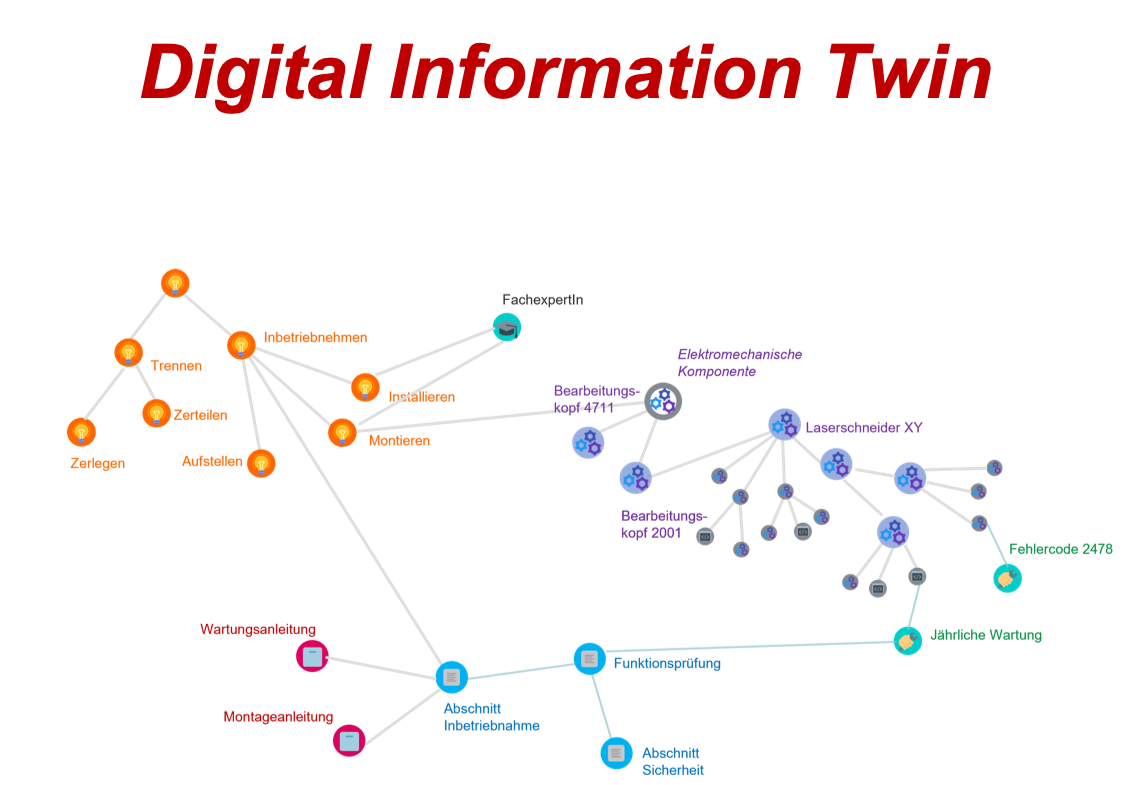
Der hier abgebildete digitale Zwilling bezieht sich auf eine beispielhafte Maschine, einen Laserschneider, der aus verschiedenen Komponenten besteht. Für die Modellierung der Komponenten verwendet man in der Regel die Stückliste des Produkts. Die Komponenten und deren Ausstattung definieren die Produktmerkmale, Produkteigenschaften und Funktionen. Auf die Komponenten und Funktionen beziehen sich Aktionen wie Wartung, Informationen wie Wartungsintervalle oder Ereignisse wie Fehler. Die verschiedenen Informationsarten im Zwilling sind durch Relationen miteinander verbunden, z.B. bezieht sich eine Fehlermeldung auf eine bestimmte Komponente und benötigt bestimmte Fehlerbehebungsaktionen.
Der digitale Informationszwilling ist damit (genauso wie der klassische digitale Zwilling von Anlagen) nicht einfach ein hierarchischer Baum, wie man ihn aus Metadatenklassifikationen kennt, sondern ein Netz von verknüpften Informationen.
Zu den produktbezogenen Metadaten kommen die Metadaten der technischen Kommunikation, u.a.:
- Informationsarten für Topics (z.B. Handlungsanweisung oder Beschreibung einer Fehlerlösung) und Dokumente (z.B. Montageanleitung oder Wartungsanleitung)
- Zielgruppe und Rolle, für die die Information relevant ist
- Produktlebenszyklusphase, auf die sich die Information bezieht, z.B. Wartung und Inbetriebnahme
- Sicherheitsrelevanz der Informationen
Ein weiterer Bestandteil des digitalen Informationszwillings ist ein generisches Informationsmodell für die technische Dokumentation des Unternehmens. Es beschreibt, welche Dokumentationsinhalte für die Produkte des Unternehmens notwendig sind. Unterliegen die Produkte zum Beispiel der Maschinenrichtlinie, dann sind Sicherheitshinweise sowie Beschreibungen der Tätigkeiten in Betrieb und Wartung Pflicht. Zudem sollen vielleicht die technischen Daten des Produkts in der Dokumentation aufgeführt werden, sowie die dazugehörige Software beschrieben werden. Das generische Informationsmodell enthält die Informationen zu den notwendigen Inhalten für die Dokumentation und speichert zudem die Information, welche dieser Inhalte es bereits im Redaktionssystem gibt.
Im Zusammenspiel mit dem Produktmodell kann so aus dem digitalen Informationszwilling abgeleitet werden, welche Inhalte für die Dokumentation einer bestimmten Komponente oder einer bestimmten Produktfunktion notwendig sind und ob es diese Inhalte schon gibt. Wenn eine Autorin z.B. den Auftrag erhält, für den beispielhaften Laserschneider die Funktionsprüfung durch Fachpersonal zu dokumentieren, kann sie über das Netz des digitalen Informationszwillings die Inhalte für diese Dokumentation ermitteln.
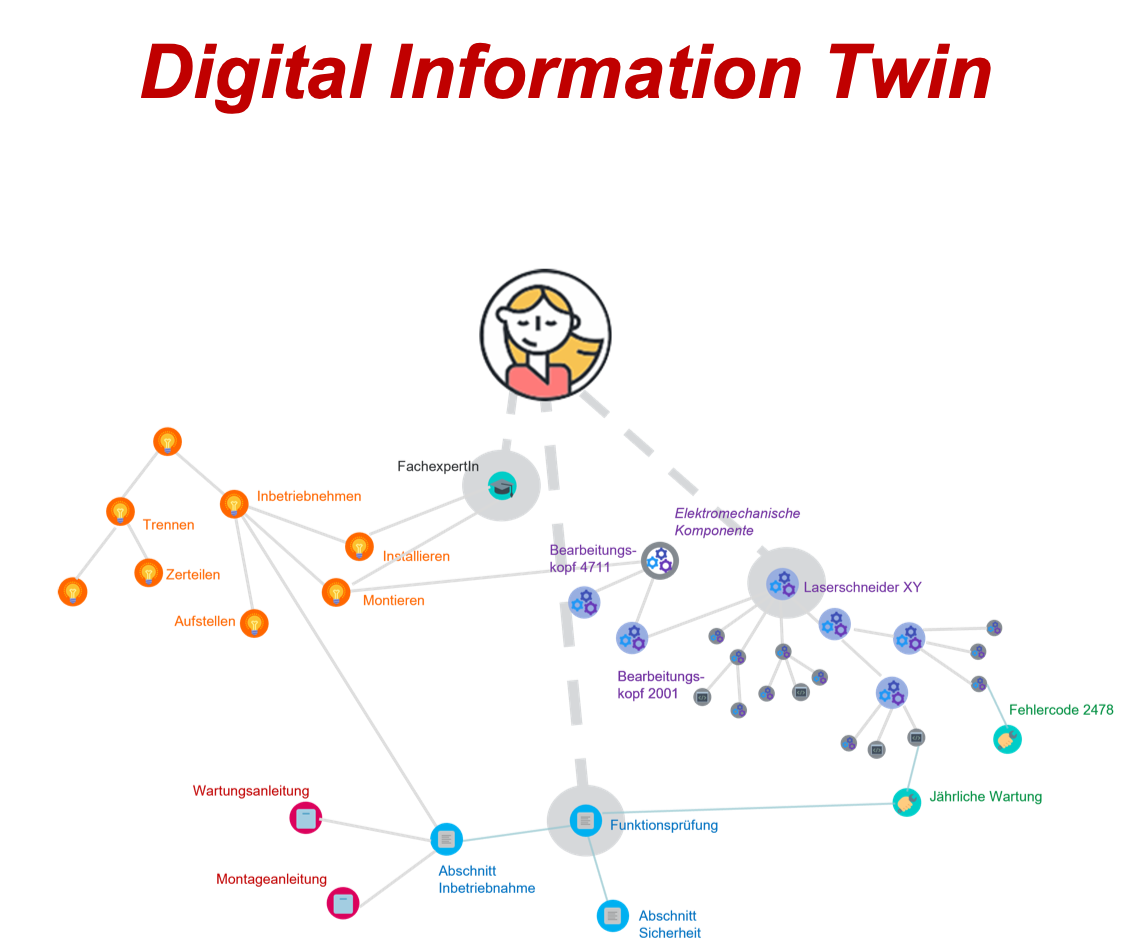
Dieser Schritt der Zusammenstellung von Inhalten entsprechend Produktkonfiguration und Inhaltsart erfolgt in Redaktionssystemen oft erst bei der Publikation, in Form eines Publikationskonfigurators. Mit dem digitalen Informationszwilling erfolgt diese Zusammenstellung außerhalb des Redaktionssystems und weit vor der Publikation – bei der Planung der Inhalte und beim Start des Redaktionsprojekts.
Diese Vorgehensweise ermöglicht es nicht nur, bereits bestehende Inhalte zu finden, sondern auch Lücken aufzudecken. Eventuell möchte z.B. die Redakteurin eine bestimmte Aktion für eine Produktvariante in einem bestimmten Szenario beschreiben und stellt fest, dass die Aktion zwar im digitalen Informationszwilling erfasst ist, aber es noch keine Inhalte für dieses Szenario gibt.
Redaktionsauftrag definieren
Der digitale Informationszwilling schafft die Möglichkeit, die Metadatenverwaltung vom Redaktionssystem zu trennen und benötigte Inhalte für ein Redaktionsprojekt dynamisch zusammenzustellen. Diese Zusammenstellung kann dann in Form eines so genannten Redaktionsauftrags an das Redaktionssystem übermittelt werden, damit die Technischen Redakteur:innen dort die Inhalte erstellen und bearbeiten können.
Das folgende Bild zeigt einen beispielhaften Redaktionsauftrag in der Oberfläche des digitalen Informationszwillings. Bereits vorhandene Inhalte sind markiert.
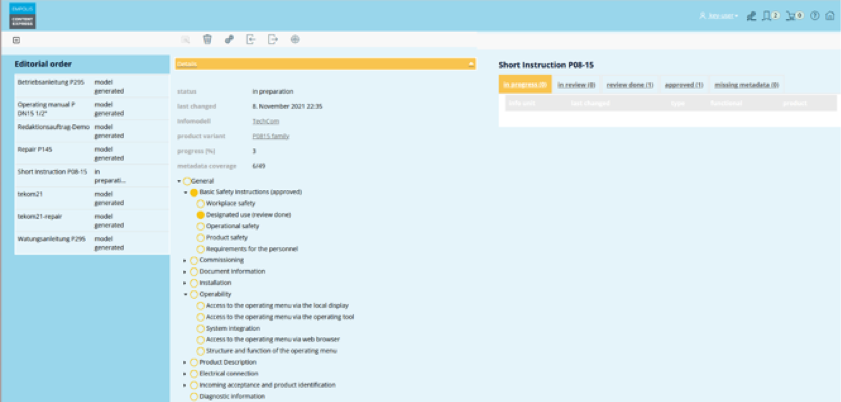
Sowohl die vorhandenen als auch die zu erstellenden Inhalte sind bereits komplett mit den Metadaten ausgestattet, die sie im digitalen Informationszwilling tragen – also z.B. Komponente, Funktion, Produktlebenszyklus usw.
Inhalte erstellen und bearbeiten
Nach der Zusammenstellung der Informationseinheiten wird der Redaktionsauftrag vom digitalen Informationszwilling an das Redaktionssystem übertragen und kann dort von der Technischen Redaktion abgearbeitet werden.
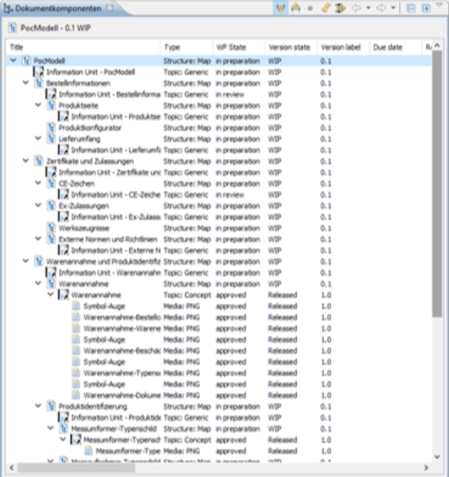
Da die Informationseinheiten bereits mit Metadaten ausgestattet sind, muss die Technische Redaktion diese Metadaten nicht im Redaktionssystem verwalten und zuordnen, sondern kann sich auf die redaktionellen Aufgaben wie technisches Schreiben, Zielgruppenanalyse, Modularisierung, Wiederverwendung und Terminologieverwaltung konzentrieren.
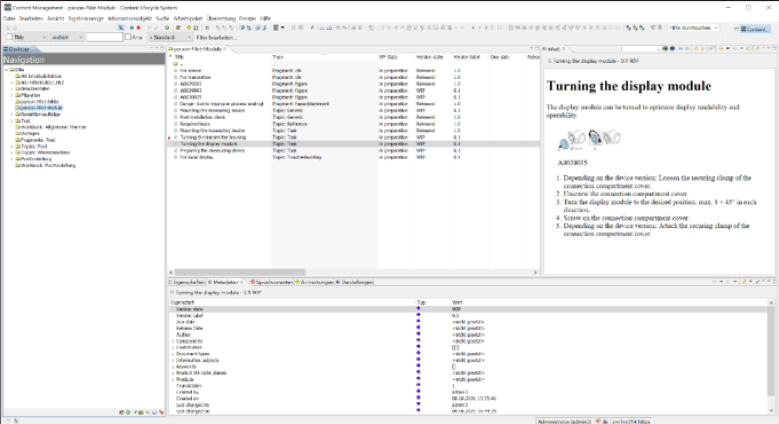
Nach der Bearbeitung werden die Angaben zu den Inhalten mithilfe des Redaktionsauftrags wieder in den digitalen Informationszwilling zurückgespielt. Die eigentlichen Inhalte verbleiben im Redaktionssystem, aber die Metadaten werden im digitalen Informationszwilling aktualisiert. Dazu gehören auch administrative Metadaten aus dem Redaktionssystem wie Autor:in oder Bearbeitungs- und Übersetzungsstatus.
Wenn der nächste Redaktionsauftrag von einem Kollegen oder einer Kollegin erstellt wird, werden dort die aktualisierten Inhalte aufgeführt und können wiederverwendet werden.
Neue Dokumentationsprozesse
Die Auslagerung des Metadatenmanagements aus dem Redaktionssystem führt auch zur Herausbildung neuer Rollen in der Technischen Kommunikation:
- Informationsarchitektur inkl. Metadatenmodellierung: Aufbau und Pflege des digitalen Informationszwillings, Erstellen von Vorlagen, Inhaltsarten und Prüfregeln
- Projektmanagement: Zusammenstellen und Überwachen von Redaktionsaufträgen
Durch den digitalen Informationszwilling wird aus dem dreistufigen Dokumentationsprozess, den wir am Anfang dargestellt haben, ein fünfstufiger Prozess, der mit dem Modellieren der Metadaten startet. Vor der Erstellung von Inhalten kommt die Pflege des digitalen Informationszwillings. Der digitale Informationszwilling beliefert nicht nur das Redaktionssystem, sondern kann auch für andere Nutzungsszenarios wie ein Content-Delivery-Portal oder einen Produktkonfigurator genutzt werden.
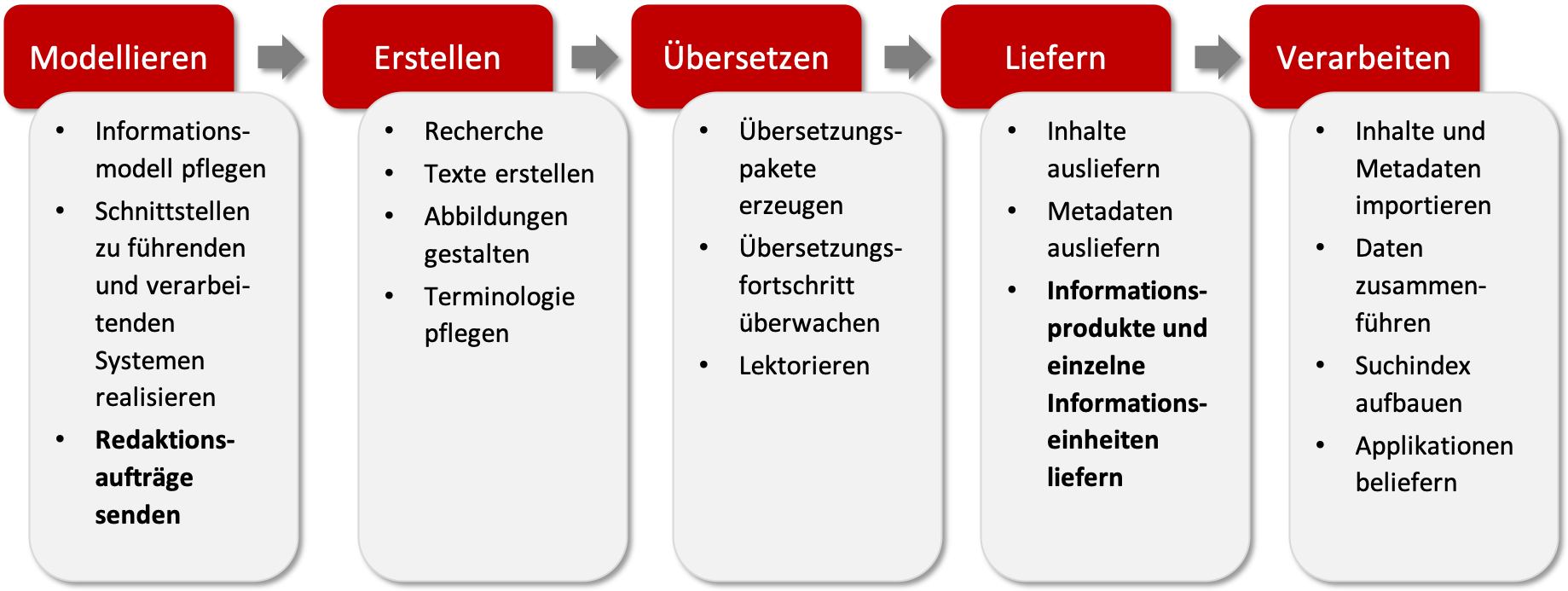
Der digitale Informationszwilling stellt die Redaktionsaufträge für das Redaktionssystem zusammen, sodass die bekannten Prozesse Erstellen, Übersetzen und Ausliefern angestoßen werden können.
Bei der Auslieferung unterscheidet sich der neue Prozess wieder vom klassischen Dokumentationsprozess: Jetzt können einzelne Inhaltsbausteine (Topics oder Informationseinheiten) statt kompletter Dokumente ausgeliefert werden, und zwar inklusive ihrer Metadaten. So können Inhalte in den Auslieferungskanälen, z.B. in einem Content-Delivery-Portal, fortlaufend aktualisiert werden (continuous delivery).
Die ausgelieferten Inhalte und die dazugehörigen Metadaten werden von den nachgelagerten Systemen weiterverarbeitet. Zur Weiterverarbeitung gehören u.a. die Darstellung auf Webseiten, der Aufbau eines Suchindex oder die Zusammenführung von Daten aus verschiedenen Quellen.
Hier finden Sie die Aufzeichnung des gleichnamigen Vortrags auf der tekom-Jahrestagung 2021:
Metadatenmodelle für die Technische Dokumentation
Erstellen Sie mit parson ein Metadatenmodell für die Technische Dokumentation!
Neuen Kommentar hinzufügen