Endress+Hauser: Automated, configuration-specific documentation
Initial situation
Endress+Hauser, a global leader in measurement and automation technology, aims to align its technical documentation with the requirements of the digital product world. Although the content is already structured in XML within a component content management system (CCMS), it lacks the level of granularity required for configuration-specific reuse.
With a continuously growing product range and increasing variant complexity, technical documentation must be aligned with specific product configurations and support targeted content reuse. At the same time, product data from different systems must be better integrated and made usable for documentation.
The project focused on the following requirements:
Providing tailored documentation for specific product configurations, including compliance with regulatory requirements
Ensuring consistent availability and usability of product data from different systems and locations for documentation purposes
Integrating additional technically relevant information for specific variants
Considering software and other technical data sources, alongside classic product data
Enabling end-to-end automation of publishing processes, particularly for PDF outputs
Project objectives
The overarching goal is to tightly integrate product data, documentation content, and processes to create a scalable foundation for configuration-specific digital documentation.
Specifically, the project pursues several strategic and operational objectives:
Developing a sustainable information architecture, including defined workflows for technical writing teams and adjacent teams such as product management
Harmonizing product data from different systems (e.g., PIM) and integrating it into a knowledge graph
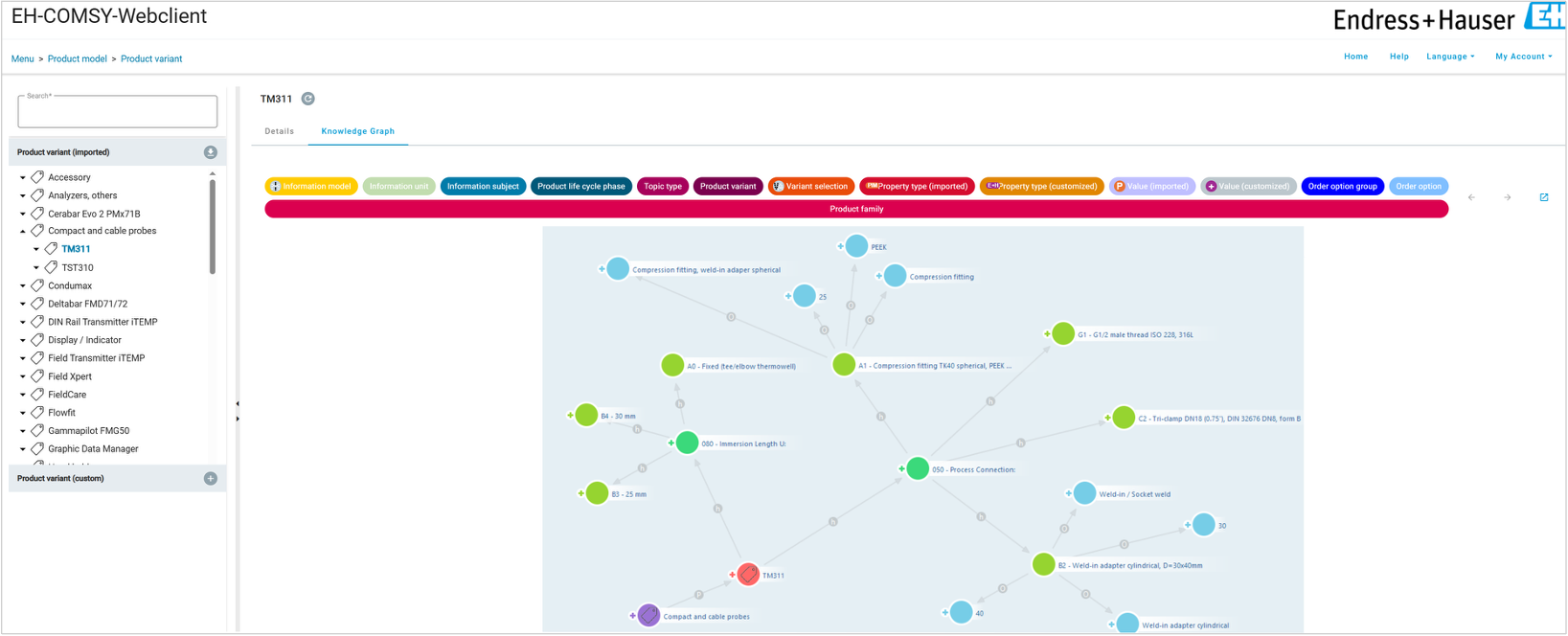
Using product data as the control basis for documentation. Variant-defining metadata should no longer be maintained manually in the CCMS, but instead originate from the knowledge graph and automatically control documentation.
Transitioning to topic-based authoring using DITA XML
- Establishing an automated publishing pipeline for PDF outputs
- Replacing the existing CCMS with Empolis Content Connect and Oxygen XML Author, including an editing component for the information architecture.
parson supports implementation
As part of a preliminary project, Empolis Content Connect was selected. The system combines a knowledge graph for managing complex product data with a DITA-based CCMS.
parson supported Endress+Hauser in implementing Empolis Content Connect across the entire content and data chain — from product modeling to publication.
Information architecture and product model
- Supporting the harmonization of product data from various product data systems
- Developing a concept for the consistent use of PIM data within the knowledge graph as well as a mechanism enabling Endress+Hauser’s information architects to independently maintain product data in the knowledge graph independently in the future
- Supporting data integration, such as software parameters, from proprietary systems into the knowledge graph as a basis for software documentation
- Providing long-term support in building a standardized, enterprise-wide product model
Implementing variant-driven documentation
Together, Endress+Hauser, Empolis, and parson implemented a concept for automatically generating documentation variants based on linked product data. This concept is based on three pillars:
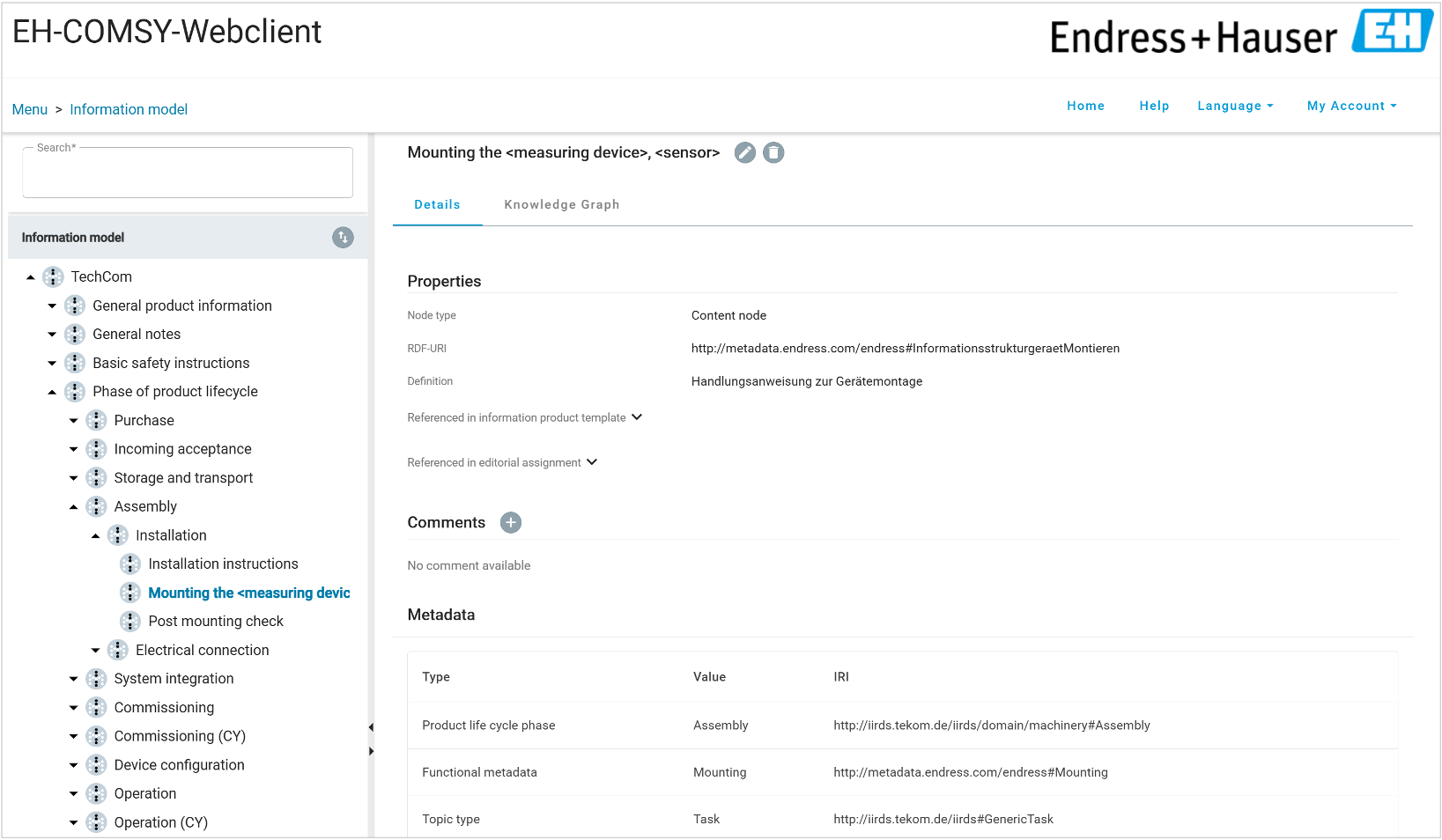
Information model
Defines categories for all editorial content in Endress+Hauser product documentation throughout the product lifecycle, from procurement and transport to commissioning and maintenance.
Product model
Contains product data imported from systems such as PIM, ERP, and software configuration
Links this data within a knowledge graph
Identifies variant-defining product characteristics for technical documentation
Variant selections
- Link the product model and the information model
- Control which documentation content is created, reused, and delivered for specific product configurations
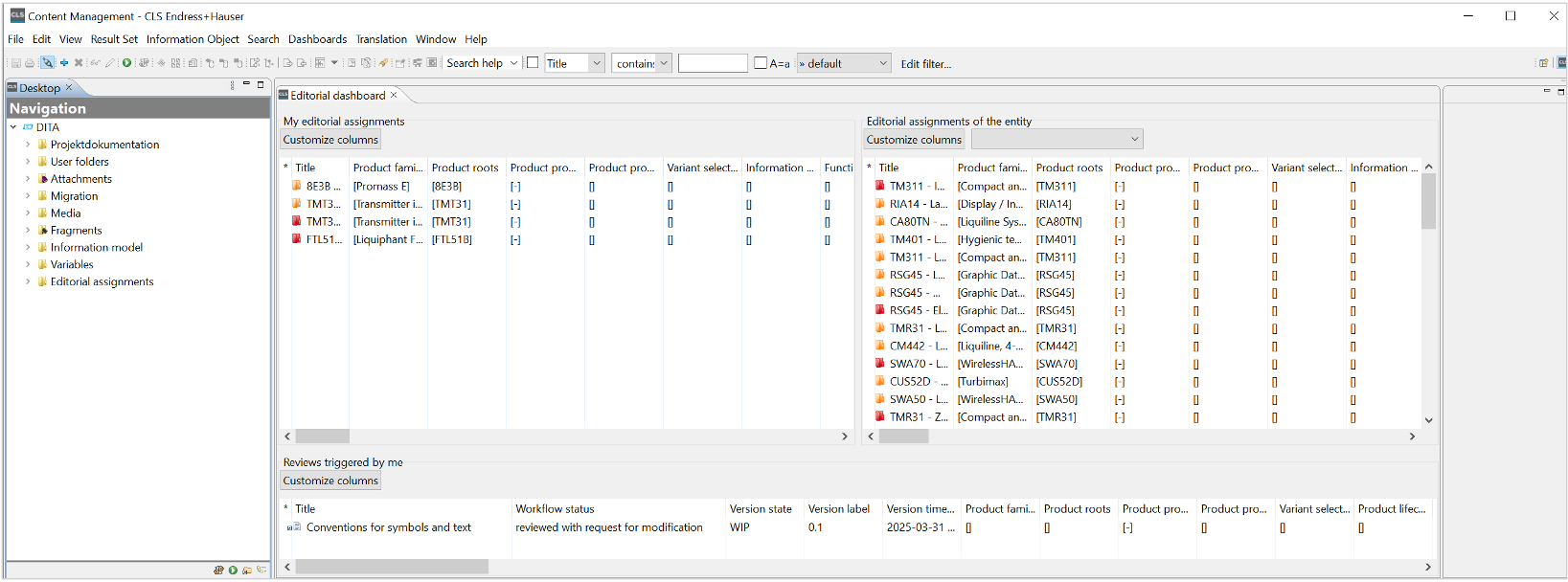
The editorial job, or authoring task, plays a central role:
- It queries the product and information model to determine which product variant and content categories require editorial content
- Based on this information, it automatically compiles the necessary information and transfers it to the CCMS
- Technical writers receive a fully configured documentation project with all the necessary information units, already enriched with metadata via the knowledge graph
Content reengineering
- Support in transitioning to topic-based writing with DITA in the CCMS
- Revising existing documentation to clearly separate information types
- Preparing for future delivery via a content delivery portal
Technical Implementation
- Customizing the DITA DTD to meet project-specific requirements
- Setting up an Endress+Hauser-specific framework in Oxygen XML Author and integrate it into the CCMS
- Developing a publication pipeline, including PDF output, using a DITA-OT plugin
Testing and quality assurance
- Designing and executing functional tests using ALM Octane
- Bug tracking and requirements management with Jira
Project results
The project established key foundations for product-data-driven, configuration-specific technical documentation:
- A sustainable information architecture
- A unified, extensible product model within the knowledge graph
- End-to-end authoring and publication workflows
This enables Endress+Hauser to automatically generate and deliver documentation tailored precisely to the corresponding order configuration.
Linking the product model and the information model via the knowledge graph represents a strategic step for us toward end-to-end automated, variant-driven documentation. parson not only supported us during system implementation but also played a key role in shaping the conceptual and structural design. Their expertise in product modeling, metadata architecture, and information architecture was particularly instrumental in establishing a robust and scalable foundation for our future documentation strategy.
Outlook
The project will be expanded step by step. The following tasks are planned:
- Content reengineering
- Expansion of the information architecture
- Integration of additional data sources
- Further harmonization of product data at corporate level
- Technical support for migrating legacy data into the new CCMS
parson will continue to support Endress+Hauser with the following:
- Adaptations to the DITA Open Toolkit
- Further development of Oxygen XML and editorial workflows
- Content engineering services
- Optimization of layouts and PDF output
These services ensure that parson remains a key partner in the digitalization of technical documentation, with a focus on content strategy, information architecture, and smart, product-data-driven automation of documentation processes.
About Endress+Hauser AG
Endress+Hauser AG is a leading global supplier of measuring instruments, services, and solutions for industrial process engineering. The company offers process solutions for flow, level, pressure, and temperature measurement, for analytical measurements, measurement recording, and digital communication, optimizing processes in terms of the economic efficiency, safety and impact on the environment. Endress+Hauser’s clients operate in a variety of industries, including chemicals, energy and power plants, basic materials and metals, food, life sciences, oil and gas, and water/wastewater.