Semantic Wikis. Or How Malta Became Semantic
Corresponding service: Knowledge graphs
Recently I read a wiki article about Malta. My friend Sarah wrote it. I knew Malta was a small island. I knew it was in the Mediterranean. What I did not know was that Malta was one of the smallest states in the world. I also learned that the capital of Malta is Valletta. Naturally I concluded that Valletta was located in Malta. Most of us would. Computers would not. Because the wiki article was not machine-interpretable. It had no semantic capabilities.
The Semantic Web
The Word Wide Web stores billions of Web pages with an incredibly large amount of data, unstructured or semi-unstructured and only designed to be read by humans. The Semantic Web will take us to the next level. It will no longer store mere information. It will convert the Web into a Semantic Web, into "a web of data that can be processed directly and indirectly by machines", as the inventor of the World Wide Web, Tim Berners-Lee, puts it. Content will become meaningful to computers.
The concept of creating a Semantic Web was developed in the 1960s. Yet the project has been developing slowly; the Semantic Web is still immature. Why does it take so long? There are several reasons:
- The amount of data on the Internet has been growing immensely. Tagging this huge amount of content with additional semantic information is an almost impossible task.
- Other projects look more exciting or promise more or more immediate return.
- The Semantic Web will not succeed without a standardized concept.
Semantic Technologies
he Semantic Web applies languages that are specifically designed for data: Resource Description Framework (RDF), Web Ontology Language (OWL), and the query language SPARQL.
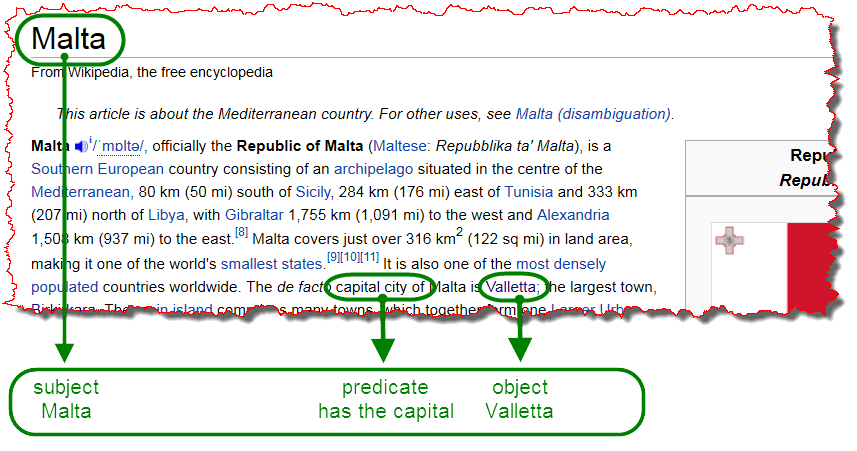
RDF defines meaning and relation of content. It describes triples that bundle content in a way that can be compared with the main constituents of a sentence: the subject, the predicate and the object.
Coming back to my previous Malta example, the subject there would be "Malta", the predicate "has the capital", and the object "Valletta". This way, computers could conclude that Valletta was a city located in Malta. They just need to know that the predicate "has the capital" always asks for a city located in the country (or region) that represents the subject.
RDF begins by drawing a basic knowledge model, irrespective of the way in which the content will be presented. The W3C recommends the XML-based model (RDF/XML), which is also the most common format. In a later stage, the W3C will standardize the model by applying the RDF schema, which is similar to a DTD in XML.
OWL or OWL2 describe complex ontologies in an abstract manner. Ontologies describe joint relations and properties of subjects of the same kind. For example, we could define that each subject of the category "country" must have the predicates "has so many inhabitants" and "has the capital".
SPARQL is an RDF query language for databases that retrieves and manipulates data stored in RDF format.
The Semantic Web also includes annotations. "Regular" annotations are used by programmers to implement meta data into source code. Semantic annotations describe afore mentioned tagging of content to give content meaning. Each semantic annotation provides specific semantic information about the subject.
Semantic Wikis
If we apply the main principles of the Semantic Web to small and self-contained platforms, we can define standards and adjust them to our individual needs more easily. This is where the wiki comes in. Wikis work best with clearly defined topics and text categories. Wikipedia is based on the same idea: Although not entirely topic-based, it only publishes categorized dictionary articles.
Before we define the content structure of a wiki, we need to ask ourselves:
- What kind of information do we want to collect?
- How do we categorize that information?
- How do we present information of the same kind consistently?
Once we have answered these questions, we are close to creating a fully functioning semantic wiki. All we need is wiki software that supports semantic annotations and queries.
Semantic MediaWiki
Semantic MediaWiki (SMW) is an extension of the well-known wiki software MediaWiki. Equipped with semantic technologies, the software fully applies the standards of the Semantic Web. As in RDF, content in SMW is bundled and consists of subject, predicate, and object:
- The subject is the particular wiki page that is filled with information.
- The predicates are the "properties", individually defined by the wiki author.
- Each property can be used on different wiki pages, the subjects. That means that semantic annotations always occur on a wiki page. For each wiki page, the author applies a value (object) to a property (predicate). By defining a property, the author determines what kind of values should be used: numeric values for instance, or other wiki pages.
If Sarah, the author of the wiki article about Malta, wants to make her article machine-interpretable, she has to:
- Create another wiki page about Valletta.
- Define properties in separate property pages. Each property has its own property page.
- Insert semantic annotations into the Valletta page.
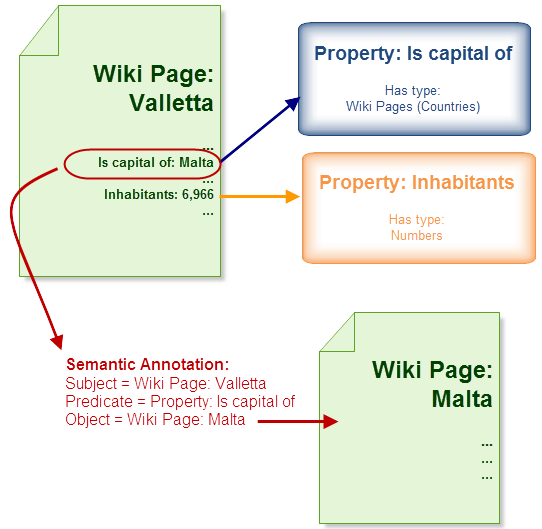
Each semantic annotation stores information about the subject. In Sarah's Valletta article, which is the subject, the semantic annotations are the predicate (is capital of) and the object (the wiki page about Malta). SMW lets us retrieve this information in two ways:
- By querying the values of a specific wiki page or
- By querying wiki pages that contain specific values for specific properties.
Semantic annotations create links between wiki pages. Sarah adds them to create a link between the Valletta and the Malta articles. Or semantic annotations store values for the same properties on topic-related wiki pages to be later processed by computers, for example, the value "Inhabitants" in the Valletta article).
Increasing Semantic Data
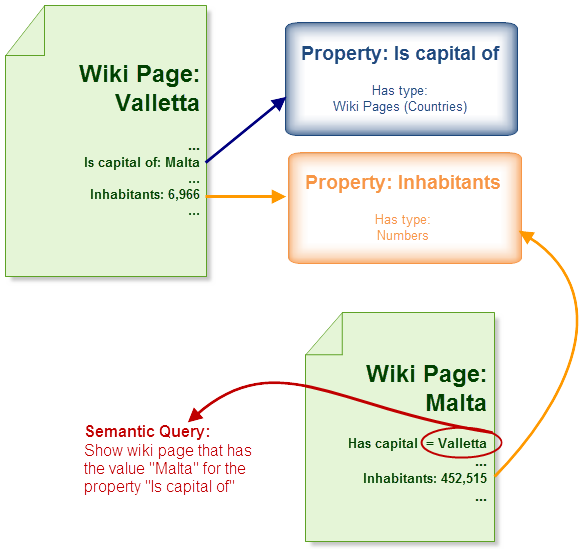
In a next step, Sarah revises her wiki article about Malta. She thinks about general relations between cities and countries. Cities are always located in a country and one of these cities usually is the capital. In her Valletta article, Sarah had already "told" the computer that Valletta is the capital of Malta. And Sarah hates telling the same thing twice. So in the Malta article, Sarah queries the following: "Show me the city that is the capital of "Malta". The wiki displays "Valletta". Now a happy Sarah adds a semantic annotation about the inhabitants of Malta to her Malta article. She uses the same property as in the Valletta article.
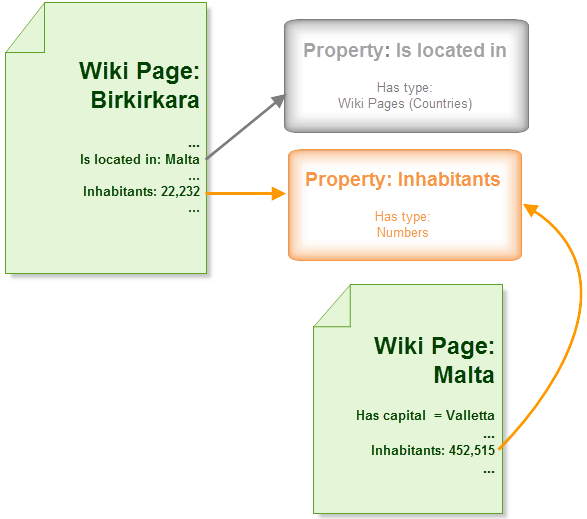
Sarah now finds an article about Birkirkara, another city in Malta. This page has no semantic annotations. Again, she adds a semantic annotation about the inhabitants to that page. Sarah also defines a new property to store the relation between Birkirkara and Malta.
Remembering her last holiday in Malta, Sarah creates articles about Mosta and Paola, two of her favorite cities. She includes the same annotations as in her Birkirkara article. Afterwards she checks the functionality of her wiki by querying a list of cities located in Malta. The wiki displays the correct list. Sarah could also arrange the list of cities by the number of inhabitants.
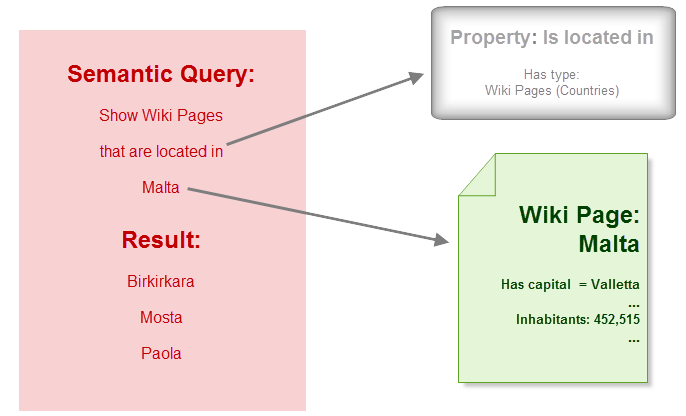
SMW queries the semantic annotations and automatically displays the data stored in the different wiki pages.
But one city is missing in the list. Valletta. Sarah realizes: She has not "told" the wiki that Valletta is located in Malta. She only "told" the wiki that Valletta was the capital. Sarah also hates telling things that are obvious. A capital is always located in the respective country! So she "tells" the wiki this by changing the definition of her property "is the capital of". We call this SMW feature inferencing.

Processing Semantic Annotations
Since SMW allows us to freely define many different properties we can build an ontology for our topics. We can enter visible or invisible semantic annotations on wiki pages.
That means that Sarah cannot only use properties to store content but also to determine meta data, such as the target audience or the working status of a wiki page. The wiki queries these annotations through templates, which determine, based on the value of a property, whether a wiki page should display only selected content or change its looks. For example, Sarah could mark the current state of her Malta page to display a watermark as long as she is working on that article.
Running a Semantic Wiki
Semantic MediaWiki combines the benefits of wiki software and a database. But since semantic annotations are simply inserted in continuous text, we need to be extremely thorough with the data. If we set properties incorrectly or do not set them at all, our queries will deliver false results. Writing wikis is collaborative work. Several authors together create the content that will be immediately available to other authors or readers. And the greater the number of authors, the greater the danger will be that semantic annotations are improperly set. If we want a well-functioning semantic wiki, we need to:
- Create a semantic concept (ontology).
- Make sure that the authors follow that concept.
To achieve the second goal, we can improve SMW using forms. We can predefine the semantic annotations that are required for wiki pages belonging to a specific category, for example, a country category. By using forms, the wiki always asks for the same properties when creating articles for a category. The entered values are automatically turned into semantic annotations. This way, wiki pages can be standardized.
Sources:
http://www.w3.org/standards/semanticweb/
http://semantic-mediawiki.org/
http://en.wikipedia.org/wiki/Semantic_Web
http://en.wikipedia.org/wiki/Malta