Was Redakteure wissen
Zugehörige Leistung: Knowledge-Graphen
(Der Artikel erschien in der Zeitschrift "technische kommunikation", Ausgabe 06/2016. Die englische Version ist im Online-Magazin technical communication verfügbar.)
Mit einem knappen Gruß lege ich das abgezählte Geld in die kleine Schale. Der Mann am Lenkrad schaut auf, nickt und drückt ein paar Knöpfe. Noch bevor sich die Tür hinter mir schließt, spuckt der kleine Drucker ein Stück Papier aus.
So oder ähnlich geht es wohl vielen, die morgens mit dem Bus zur Arbeit fahren. Der Fahrer weiß sofort, was ich will. Und auch ich weiß, was zu tun ist, wenn ich mit dem Bus fahre. Haltestelle, Fahrplan, Bus, Einsteigen, Busfahrer, Fahrschein, Aussteigen. Das gehört in der Regel zu einer Busfahrt. Dieses allgegenwärtige Wissen ist für uns selbstverständlich. Wir reden nicht groß darüber. Es hilft uns aber, den Alltag zu meistern.
Im Wissensmanagement wird das allgegenwärtige Wissen als implizites Wissen bezeichnet. Implizites Wissen erwerben wir, indem wir eine ähnliche Situation wiederholt erleben. Implizites Wissen wird nicht unterrichtet, ist nicht aufgeschrieben und nicht verbalisiert. Daher können wir implizites Wissen nur schwierig teilen.
Implizites und explizites Wissen
Aber natürlich können wir versuchen, dieses Alltagswissen aufzuschreiben und uns darüber zu unterhalten. Doch sobald wir das tun, externalisieren wir das implizite Wissen und machen daraus explizites Wissen. Das explizite Wissen kann durch Schrift oder Sprache vermittelt werden. Dadurch ist explizites Wissen speicherbar, vermittelbar und vielseitig nutzbar. Wissen so nutzbar zu machen, das ist zentraler Bestandteil des Wissensmanagements1.
Wenn ich nun aus dem Bus steige, ins Büro gehe und mich an den Schreibtisch setze, dann mache ich als Technischer Redakteur etwas sehr Ähnliches. Ich helfe dabei, Wissen zu externalisieren. Ich rede mit Fachleuten über Dinge, die ihnen alltäglich erscheinen, die sie aber nicht aufgeschrieben haben. Dann erstelle ich ein Informationsprodukt und mache aus dem impliziten Expertenwissen für andere nutzbares explizites Wissen.
Sammeln und modellieren
Kaum an meinem Schreibtisch angekommen, lese ich meine E-Mails. Der Produktmanager will die neue App „Napsor“ dokumentieren. Wir setzen uns zusammen und sammeln in einem ersten Brainstorming alle wichtigen Aspekte. Was kann die App? Wer benutzt die App? Was will der Nutzer damit vermutlich machen? Hat die App mehrere Teile?
Die Antworten auf meine Fragen schreibe ich in eine Mindmap. Nachdem wir fertig sind, enthält meine Mindmap eine Vielzahl an sortierten Stichpunkten (Abb. 01). Die sortierten Stichpunkte bilden später die Struktur meines neuen Informationsprodukts. Die Mindmap enthält aber nicht nur die Grobstruktur meiner Technischen Dokumentation. Die Map umfasst auch alle wichtigen Konzepte rund um die App, zum Beispiel Funktionen, Nutzer und die grafische Oberfläche. Sie beschreibt die inhaltliche Domäne „Napsor“.
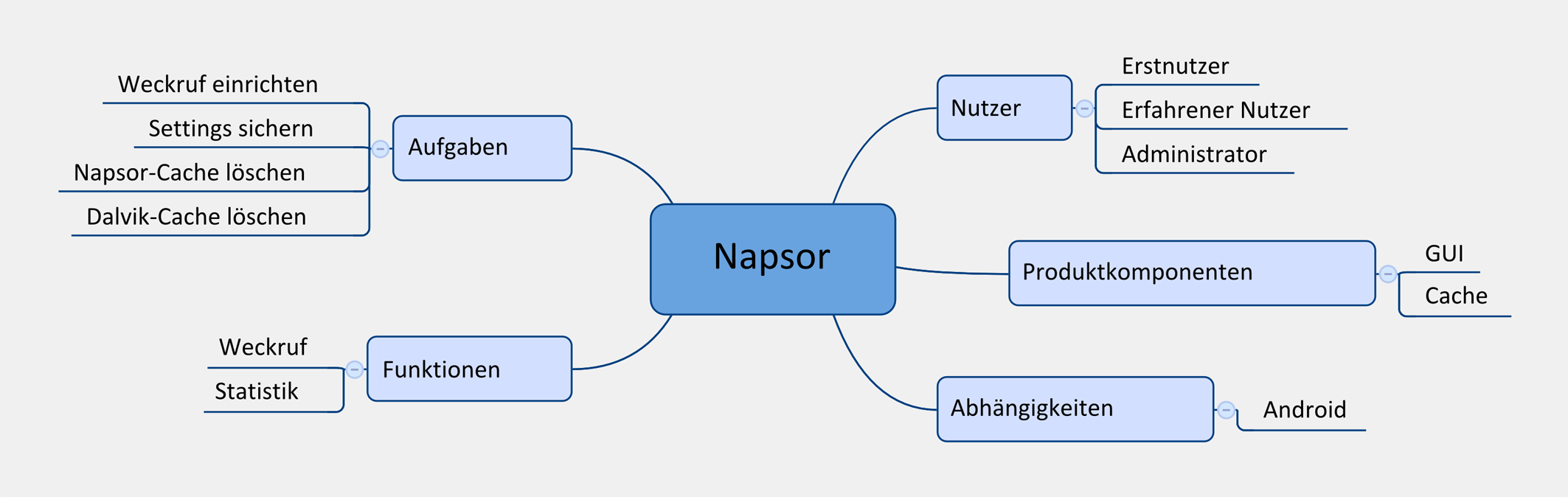
Identifizieren und erfassen
Ähnlich arbeitet der Wissensmanager. Um ein Wissensmodell zu entwickeln, muss er die wichtigen Bestandteile einer Domäne identifizieren. Das Ergebnis seiner Arbeit ist aber meist kein klassisches Informationsprodukt und auch keine Mindmap. Der Wissensmanager erstellt eine formalisierte Beschreibung der Domäne. Was bei mir in der Mindmap steht, das erfasst der Wissensmanager standardisiert. Dafür steht ihm ein großer Werkzeugkasten zur Verfügung. Einige der Werkzeuge stellt das Standardisierungsgremium W3C bereit.
Für die Wissensmodellierung hat das W3C unterschiedliche Sprachen definiert. Die Sprachen liefern das Vokabular für den Wissensmanager. Die gebräuchlichsten Sprachen sind RDF, RDFS und OWL. Während meine Mindmap schnellen visuellen Zugang zu den Teilen meiner Domäne bietet, sind standardisierte Wissensmodelle automatisiert auswertbar. Zum Beispiel verwenden die großen Suchmaschinen im Internet standardisierte Wissensmodelle, um ihre Suchergebnisse mit Informationen anzureichern.
Klassen und Instanzen
Wenn ein Wissensmanager ein formalisiertes Wissensmodell erstellt, dann sucht er in der großen Menge an Informationen über seine Domäne nach Gemeinsamkeiten. Wie in meiner Mindmap kann er auch in seinem Wissensmodell Bestandteile der Domäne gruppieren. In der Mindmap bilden zum Beispiel die Unterpunkte „Erstnutzer“ und „Erfahrener Nutzer“ eine Gruppe. Diese Gruppe habe ich in meiner Mindmap „Nutzer“ genannt. In der Wissensmodellierung entsprechen solche Gruppen jeweils einer Klasse.
Klassen gruppieren die Bestandteile einer Domäne. Die Mitglieder einer Gruppe haben gleiche Merkmale. Was in meiner Mindmap ein Knoten „Nutzer“ mit den Unterpunkten „Erstnutzer“ und „Erfahrener Nutzer“ ist, das entspricht in OWL der Klasse „Nutzer“ mit den Unterklassen „Erstnutzer“ und „Erfahrener Nutzer“ (Abb. 02).
Je detaillierter ein Wissensmodell ist, desto mehr Klassen und Unterklassen enthält es. Ist das Wissensmodell sehr detailliert, dann bilden die Klassen mit ihren Unterklassen eine hierarchische Struktur. In dieser Hierarchie steht jede Klasse in einer Ist-ein-Beziehung zu der Oberklasse. So ist in unserem Beispiel ein „Erfahrener Nutzer“ auch ein „Nutzer“2.
In meiner Mindmap stehen aber nicht nur abstrakte Gruppen, sondern auch ganz konkrete Inhalte. So findet sich unter dem Knoten „Anleitung“ der Unterpunkt „Napsor-Cache löschen“. Der Unterpunkt „Napsor-Cache löschen“ bildet keine Untergruppe, sondern ist ein Mitglied der abstrakten Gruppe „Anleitung“. Auch für diese Fälle hält die Wissensmodellierung eine Lösung bereit. Um ein konkretes Mitglied einer Klasse zuzuweisen, modelliert der Wissensmanager den konkreten Inhaltsblock „Napsor-Cache löschen“ als eine Instanz der Klasse „Anleitung“. Eine Instanz ist Mitglied einer oder mehrerer Klassen und teilt deren Eigenschaften.
XML-Repräsentation der Klassen "Nutzer" und "Erstnutzer" in OWL:
<Declaration>
<Class IRI="#Nutzer" />
</Declaration>
<Declaration>
<Class IRI="#Nutzer" />
</Declaration>
<SubClassOf>
<Class IRI="#Erstnutzer" />
<Class IRI="#Nutzer" />
</SubClassOf>
Ein Tipp zur Wissensmodellierung
Für die Wissensmodellierung eignet sich die Software Protégé. Mit ihr sind zum Beispiel die Abbildungen in diesem Beitrag entstanden. Die Open-Source-Anwendung ist unter http://protege.stanford.edu verfügbar.
Klassen und Merkmale
Nach meinem Meeting mit dem Produktmanager hole ich mir erstmal einen Kaffee. Dann geht es zurück in mein Büro. Die Mindmap soll mir nun beim Schreiben helfen. Also fahre ich meinen Rechner hoch und starte unser Redaktionssystem. Die Mindmap ist ein recht einfaches Mittel, um Inhalte zu strukturieren und relevante Informationen einer Domäne abzubilden. Mit dem Redaktionssystem steht mir nun ein mächtigeres Werkzeug zur Verfügung. Hier kann ich Textmodule schreiben und verwalten. Später erstelle ich aus den Modulen Informationsprodukte. Dabei sind in meinem Redaktionssystem Klassen, Unterklassen und Instanzen allgegenwärtig.
Wer modularisiert, der dokumentiert und gruppiert seine Module oft nach Inhaltsklassen und Merkmalen des Produkts. Etablierte Methoden wie die PI-Klassifikation helfen bei der Modellierung des Domänenwissens auch ohne Kenntnisse von Modellierungssprachen3. So sind zum Beispiel all meine Textbausteine mit Warnhinweisen Instanzen der Klasse „Warnhinweis“. Und die Klasse „Warnhinweis“ ist wiederum eine Unterklasse von „Hinweis“. Entsprechend der Klassenlogik teilen alle Hinweise gemeinsame Merkmale. Sie sind ergänzende Information und werden alle nach der Publizierung ähnlich dargestellt.
Eigenschaften und Tripel
Um aus Textmodulen Informationsprodukte zu machen, bieten Redaktionssysteme meist eine weitere Informationsebene. Metadaten kennzeichnen Inhaltsmodule, die relevant für bestimmte Zielgruppen, Produkte oder andere Varianten sind. So ist zum Beispiel meine Anleitung „Napsor-Cache löschen“ für Administratoren wichtig. Also setze ich „Zielgruppe“ auf den Wert „Administrator“. Über Filter und Publikationsszenarien kann ich später ein Handbuch für Administratoren publizieren.
Auch für den Wissensmanager sind diese Metadaten wichtig. Er verwendet in seinem Wissensmodell Eigenschaften. In unserem Beispiel hat die Anleitung „Napsor-Cache löschen“ die Eigenschaft „ist wichtig für“. Als Wert der Eigenschaft setzt der Wissensmanager „Administrator“. Der Wert ist aber nicht einfach eine Buchstabenfolge. In dem Wissensmodell ist „Administrator“ eine weitere Unterklasse von „Nutzer“. Die Eigenschaft „ist wichtig für“ verknüpft also die Anleitung „Napsor-Cache löschen“ mit einem Nutzer aus der Klasse „Administrator“. So modelliert der Wissensmanager eine Beziehung zwischen den Teilen der Domäne. Die Beziehung hat die Form Subjekt-Prädikat-Objekt4.
„Napsor-Cache löschen“ – „ist wichtig für“ – „Administrator“ – diese Beziehung wird in der Wissensmodellierung als Tripel bezeichnet. Alle Aussagen in einem standardisierten Wissensmodell bilden solche Tripel (Abb. 03). Der Wissensmanager verwendet in seinem Wissensmodell natürlich nicht nur eine Eigenschaft, sondern viele. Für alle Beziehungen zwischen Klassen und ihren Instanzen, die dem Wissensmanager wichtig sind, kann er Eigenschaften frei definieren. Da die Eigenschaften Tripel bilden, entstehen zahlreiche Verknüpfungen zwischen Klassen und Instanzen. Das Ergebnis ist ein Netz aus Subjekt-Prädikat-Objekt-Beziehungen.

Würde ich alle Subjekt-Prädikat-Objekt-Beziehungen in der Mindmap abbilden, dann hätte ich jetzt ein Gewirr aus Knoten und Linien. Hier spielt ein standardisiertes Wissensmodell seine Vorteile aus. Mit der entsprechenden Software kann der Wissensmanager das Wissensmodell abfragen. Dabei verwendet die Software Algorithmen, sogenannte semantische Reasoner. Die Reasoner leiten aus den definierten Beziehungen weitere Tripel ab. Mit der Abfragesprache SPARQL kann der Wissensmanager dann die definierten und abgeleiteten Tripel auswerten. So sind einfache Abfragen möglich, zum Beispiel „Zeige mir alle Anleitungen, die für Administratoren wichtig sind.“ Aber auch komplizierte Abfragen über mehrere Beziehungen hinweg lassen sich erzeugen.
Meine Anleitung „Napsor-Cache löschen“ hat nämlich nicht nur eine Beziehung zu der Klasse „Administrator“. Die Anleitung hat auch die Eigenschaft „ist relevant für Produktkomponente“ mit dem Wert „Napsor-Cache“. „Napsor-Cache“ hat wiederum die Eigenschaft „ist Teil von“ mit dem Wert „Napsor“. Und „Napsor“ hat die Eigenschaft „läuft unter Betriebssystem“ mit dem Wert „Android“. Daraus ergeben sich folgende neue Tripel:
-> „Napsor-Cache löschen“ – „ist relevant für Produktkomponente“ – „Napsor-Cache“
-> „Napsor-Cache“ – „ist Teil von“ – „Napsor“
-> „Napsor“ – „läuft unter Betriebssystem“ – „Android“
Aufgrund dieser Beziehungen kann ich abfragen, mit welchen Betriebssystemen sich ein Administrator auskennen muss, der mit „Napsor“ arbeitet. Für diese Abfrage hangelt sich der Algorithmus entlang der Linien im Netz und sammelt alle Informationsmodule ein, die relevant für den Administrator sind. Danach wertet er Beziehungen der Informationsmodule zu Produktkomponenten, Produkten und deren Beziehungen zu benötigter Software aus (Abb. 04).

RDF, RDFS UND oWL
Das World Wide Web Konsortium W3C entwickelt Standards zur Beschreibung von Metadaten. Am bekanntesten sind RDF, RDFS und OWL. Die Standards bauen aufeinander auf und unterscheiden sich im Umfang ihres Vokabulars.
RDF – das Resource Description Framework RDF ist ein Datenmodell mit formaler Semantik. Es ist heute wesentlicher Bestandteil des Semantischen Webs5. RDF stellt eine einfache Semantik zur Verfügung, um Aussagen über Ressourcen zu modellieren. Aussagen werden als Tripel modelliert. Ein Tripel besteht aus drei Ressourcen: Subjekt, Prädikat und Objekt.
RDF ist unabhängig von einer speziellen Repräsentation. Eine Form der Repräsentation ist XML. Als kompakteres, für Menschen leichter lesbares Format wird oft Turtle verwendet. Folgendes Beispiel zeigt eine Subjekt-Prädikat-Objekt-Beziehung in Turtle:
my:Napsor rdf:type my:AndroidApplication.
RDFS – RDF-Schema (RDFS) ist eine semantische Erweiterung von RDF. Mit RDFS lassen sich einfache Ontologien formalisieren. RDFS stellt ein Vokabular zur Modellierung von Anwendungsdomänen bereit, mit dem die Klassen der Domäne, Eigenschaften und Relationen untereinander modelliert werden können6.
Durch Zusammenfassen von Ressourcen mit gleichen Eigenschaften in einem Typsystem lässt sich die Semantik der verwendeten RDF-Elemente formal festlegen, so dass Unterklassen und Unter-Properties Teilmengen ihrer Oberklasse und ihrer ober-Properties sind. Folgendes Beispiel zeigt eine Klasse-Unterklasse-Beziehung in Turtle:
my:Nutzer rdf:type rdfs:class .
my:Erstnutzer rdf:type rdfs:class ;
rdfs:subClassOf my:Nutzer .
Erst das Anwendungsprogramm, das ein RDF-Schema verarbeitet, wertet die beschriebene Semantik aus und macht über Schlussfolgerungsprozesse die modellierten Zusammenhänge zugänglich.
OWL – die Web Ontology Language OWL ist ebenfalls eine Spezifikation des W3Cund basiert technisch auf RDF. OWL ist noch ausdrucksstärker als RDFS. Zum Beispiel kann OWL umfassende Einschränkungen von Eigenschaften oder Besonderheiten von Klassen und Eigenschaften abbilden7. Folgendes Beispiel zeigt eine Umkehrbeziehungen in Turtle:
my:Nutzer rdf:type rdfs:Class .
my:Erstnutzer rdf:type rdfs:Class ;
rdfs:subClassOf my:Nutzer .
Mit zunehmender Ausdrucksmächtigkeit geht aber ein Problem einher. Wissensmodelle, die das volle OWL-Vokabular verwenden, können in sich widersprüchlich sein. Algorithmen können dann nicht mehr eindeutige Auswertungen vornehmen, sondern müssen Aussagen gewichten, um Widersprüche aufzulösen. Um solche Probleme zu vermeiden, gibt es definierte Untermengen von OWL. Die Untermenge OWL DL verwendet nur einen Teil des OWL-Vokabulars. Dafür können Reasoner das Vokabular von OWL DL eindeutig interpretieren.
Während solche Abfrageszenarien auch mit konventionellen Metadaten-Modellen und intelligenter Website-Gestaltung möglich sind, erfordern sie ohne semantisches Netz einiges an Anpassungsaufwand. Mit komplexeren Anwendungsszenarien steigen zudem die Anforderungen an die Metadaten. Semantische Technologien sind genau auf solche Szenarien ausgelegt. Der Wissensmanager kann das semantische Netz leicht erweitern. Semantische Content-Delivery-Portale übernehmen dann die Präsentation der Inhalte im Netz.
Semantische Content-Delivery-Portale
Doch was hat das mit mir zu tun? Ich bin doch Technischer Redakteur und kein Wissensmanager. Aber ganz so einfach ist es nicht. Ich schreibe Dokumentation, aber keiner liest sie. Und meine Kollegen im Support schieben seit dem letzten Android-Update Überstunden. Das soll besser werden. Ein Content-Delivery-Portal könnte die Lösung bringen.
Content-Delivery-Portale sollen Nutzer mit relevanten Informationen versorgen. Dafür verwenden sie Metadaten und ein zugrunde liegendes Wissensmodell. Wie kann also eine solche Lösung aussehen? Da semantische Netze leicht erweiterbar sind, kann der Wissensmanager Wissensmodelle aus zwei Domänen verknüpfen und so Daten aus unterschiedlichen Quellen integrieren.
Für unser Problem verbinden wir das Ticketsystem des Supports mit der Dokumentations-Website. Die Verbindung schafft eine Erweiterung unseres Wissensmodells. Wir definieren die neue Klasse „Ereignis“ und ihre Unterklasse „FirmwareUpdate“. Die Klasse „Firmware-Update“ verbinden wir dann durch eine neue Eigenschaft mit „Napsor-Cache“. Es ergibt sich folgendes Tripel: „Firmware-Update“ – „verändert Produktkomponente“ – „Napsor-Cache“.
In einem zweiten Wissensmodell für den Kunden-Support findet sich ebenfalls eine Klasse „Firmware-Update“. Hier ist sie aber eine Unterklasse von „Ticketkategorie“. Der Wissensmanager setzt nun beide „Firmware-Update“-Klassen in Beziehung und schon ergibt sich eine indirekte Verbindung zu unserer Anleitung (Abb. 05).
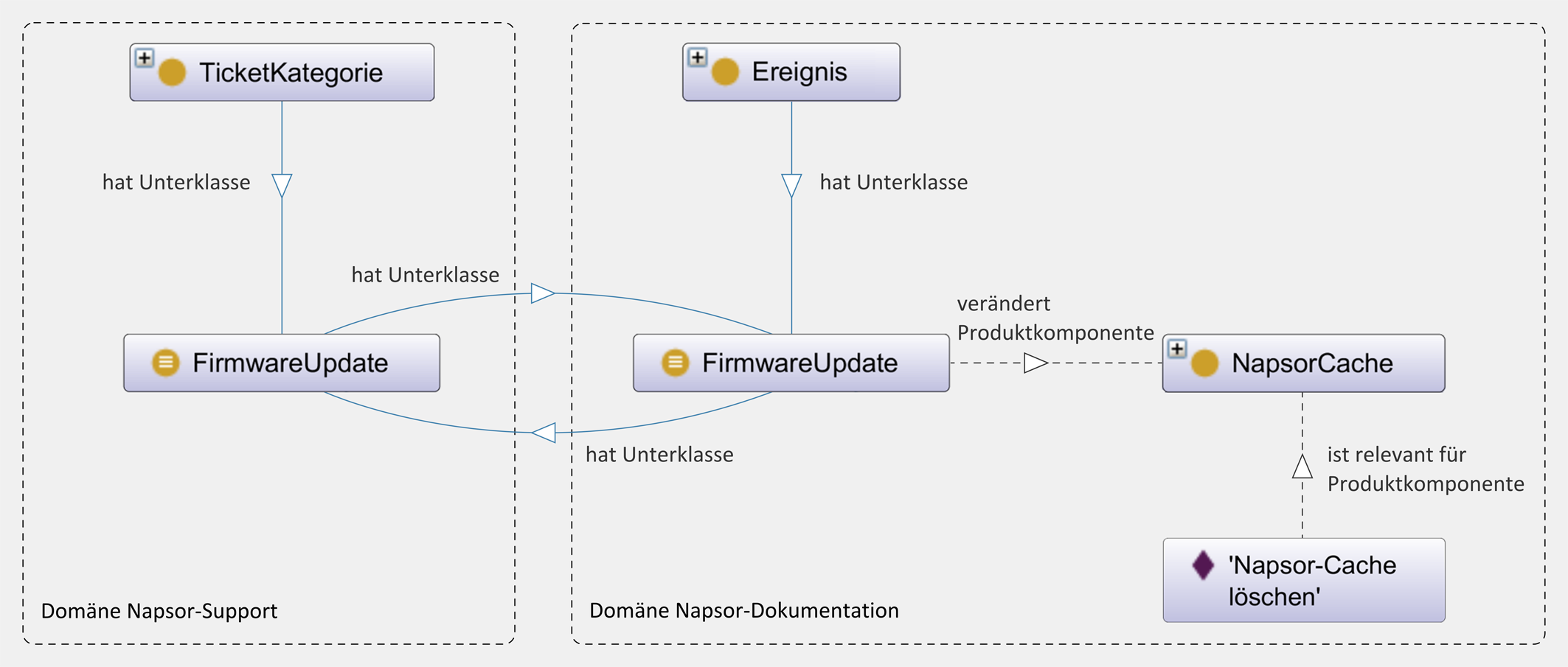
Da die Verbindung in unserem Wissensmodell abgebildet wird, muss ich als Technischer Redakteur an der Anleitung keine weiteren Metadaten ergänzen. Das semantische Netz stellt zwischen meiner Anleitung und dem Ereignis „Firmware-Update“ automatisch eine Beziehung her. Nun müssen die Ticketdaten und ihre Bearbeiter noch als semantische Tripel aus dem Ticketsystem exportiert werden. Das Content-Delivery-Portal integriert dann den Export in sein vorhandenes Wissensnetz der Domäne „Napsor“.
Wenn mein Kollege aus dem Support sich nun auf unserer Dokumentations-Website anmeldet, bekommt er sofort Inhalte angezeigt, die zu seinen Tickets passen. Das Content-Delivery-Portal liefert hier dem Nutzer die Informationen, die entsprechend seiner Rolle und seinen momentanen Arbeitspaketen relevant sind. Mich als Technischen Redakteur entlastet die semantische Technik bei einigen Aufgaben. Zum Beispiel muss ich keine Listen mit Verknüpfungen zu verwandten Themen mehr pflegen. Diese Verknüpfungen können nach Abfrageregeln aus dem Wissensmodell abgefragt und generiert werden. Dafür erfordern Content-Delivery-Portale mit semantischem Unterbau strukturierteres Vorgehen bei der Definition und Vergabe von Metadaten. Die Metadaten müssen abteilungsübergreifend harmonisiert werden. Aber wer sich auf diese neue Arbeitsweise einlässt, kann mit seinen Informationsprodukten genauer auf die Erfordernisse der Nutzer eingehen. Und dann wird eben aus dem Technischen Redakteur doch ein waschechter Wissensmanager.
Hierarchie und Netze
In der Wissensmodellierung mit semantischen Technologien können alle alles über alles sagen. Dieser Grundgedanke des semantischen Netzes lässt erahnen, wie vielfältig Wissensmodelle aussehen können. Doch trotz all der Vielfältigkeit kehren einige Muster immer wieder. Häufig wiederkehrende Strukturen in Wissensmodellen sind Hierarchien, Taxonomien und Ontologien.
Hierarchien
In der Wissensmodellierung sind Hierarchien Über- und Unterordnungen von Elementen. Ist jedem Element höchstens ein anderes Element unmittelbar übergeordnet, dann ergibt sich eine Baumstruktur. Der Wissensmanager spricht von einer Monohierarchie. Wenn ein Element auch mehrere übergeordnete Elemente haben kann, dann spricht der Wissensmanager von einer Polyhierarchie. Beide Formen von Hierarchien klassifizieren Objekte, indem sie Objekte in Gruppen einteilen und in die Hierarchie einordnen. Oft drückt die Rangordnung eine Wertigkeit aus und geht vom Allgemeinen zum Speziellen. Hierarchien sind einfacher zu erfassen als komplexe Netzwerkstrukturen.
Taxonomien
Taxonomien sind monohierarchisch strukturierte Klassifikationen: Jeder Klasse ist nur einer Oberklasse zugeordnet, sodass die gesamte Klassifikation eine Baumstruktur hat. Je näher an der Wurzel ein Element eingeordnet ist, desto allgemeiner ist die Information zu diesem Element. Mit zunehmender Verzweigung der Taxonomie wird das hinterlegte Wissen immer spezifischer. Durch diese Art der Klassifizierung von Wissensbereichen innerhalb einer Hierarchie entsteht eine einfache Semantik. Bezogen auf Dokumente und Inhalte wird der Begriff Taxonomie für ein Klassifikationssystem oder eine Systematik verwendet. Beispiele für Klassifizierungen sind Sortierung von Metadaten und semantische Ablagestrukturen.
Was sind Taxonomien nicht? Taxonomien sind keine Zuordnung von Objekten und ihren Teilen. Ein untergeordnetes Element kann kein Teil des übergeordneten Elements sein. In einer Taxonomie steht ein untergeordnetes Element in einer „Ist-ein“-Beziehung zu dem übergeordneten Element. Zum Beispiel ist ein Hase ein Säugetier. Eine Hasenpfote hingegen ist weder ein Hase noch ein Säugetier.
Ontologien
Werden die Objekte einer Hierarchie durch logische Beziehungen miteinander verknüpft, dann bilden sich Netze. Diese Netze sind Ontologien. In Ontologien sind die Objekte in Klassen und Unterklassen eingeteilt. Die Klassen haben wiederum Mitglieder, die Instanzen. Eine Instanz ist eine konkrete Ausprägung der Klasse. Eigenschaften beschreiben, welche logischen Beziehungen zwischen den Klassen und ihren Mitgliedern bestehen. Eigenschaften werden in Ontologien vererbt. Hat zum Beispiel die Oberklasse „Nutzer“ die Eigenschaft „hat Nutzernamen“, dann hat auch die Unterklasse „Erstnutzer“ diese Eigenschaft. Zur Beschreibung von Ontologien werden formale Sprachen verwendet, zum Beispiel RDF-Schema und OWL. Da diese Sprachen standardisiert sind, können sie durch Algorithmen abgefragt werden. Folgendes Beispiel in der Abfragesprache SPARQL listet alle Betriebssysteme auf, die für die Anleitung „Napsor-Cache löschen“ relevant sind:
SELECT ?os
WHERE {my:NapsorCacheLöschen my:istRelevantFuerProduktkomponente ?prodkomp .
?prodkomp my:istTeilVon ?prod .
?prod my:laeuftUnterBetriebssystem ?os. }
Links und Literatur
1 Nonaka, Ikujiro; Takeuchi, Hirotaka (1995): The knowledge creating company: How Japanese companies create the dynamics of innovation.Oxford University Press: New York.
2 Sowa, John F. (2000): Knowledge Representation: Logical, Philosophical, and Computational Foundations. Brooks Cole Publishing Co.: Pacific Grove.
3 Ziegler, Wolfgang (2014): PI ist Klasse! Einsatz und Nutzen von (PI)-Klassifikationen fur die modulare Informationserfassung. tekom Jahrestagung, Stuttgart.
4 Semantic Web Best Practices and Deployment Working Group (2005): Representing Classes As Property Values on the Semantic Web: W3C Working Group Note 5 April 2005. https://www.w3.org/TR/swbp-classes-as-values/.
5 RDF Working Group (2014): RDF 1.1 Primer: W3C Working Group Note 24 June 2014. https://www.w3.org/TR/2014/NOTE-rdf11-primer-20140624/.
6 RDFS Working Group (2014): RDF Schema 1.1: W3C Recommendation 25 February 2014. https://www.w3.org/TR/rdf-schema/.
7 OWL Working Group (2012): OWL 2 Web Ontology Language Primer (Second Edition): W3C Recommendation 11 December 2012. https://www.w3.org/TR/2012/REC-owl2-primer-20121211/.
Zum Weiterlesen
- Allemang, Dean; Hendler, Jim (2011): Semantic Web for the Working Ontologist: Effective Modelling in RDFS and OWL. Morgan Kaufmann, Waltham 2011,2nd Edition.