I don't have to know that! Knowledge modeling and technical communication
Corresponding service: Knowledge graphs
This article was published in the tc world technical communication e-magazine.
I say hi and throw some coins in a small tray. The driver looks up, nods, and presses a few buttons. The small printer produces a piece of paper and the doors close behind me.
This probably sounds familiar to all who travel to work by bus. The driver knows exactly what I want, and I know what to do on the bus. Bus stop, bus schedule, bus, hop in, driver, ticket, hop out. All this is part of a bus ride. This kind of knowledge is ever-present. We don't talk much about it, but it helps us cope with everyday life. In knowledge management, this ever-present knowledge is called tacit knowledge. We acquire tacit knowledge by experiencing a similar situation repeatedly. It is not taught; it is neither written down nor verbalized. Therefore, tacit knowledge is hard to share.
Implicit and explicit knowledge
Even though it’s not easy, we can try to write down and talk about our tacit knowledge. But as soon as we do, we externalize it and turn it into explicit knowledge. Explicit knowledge can be conveyed through writing or talking. As a result, explicit knowledge can be stored, shared, and used in many ways. Codifying knowledge and making it available like this, is the key component of knowledge management1.
When I get off the bus and sit down at my desk, I do something similar. As a technical communicator, I help externalizing knowledge. I interview experts and talk about things they take for granted and therefore haven’t written down. I do write them down and create and publish an information product. The tacit expert knowledge turns into explicit knowledge that can be used by others.
Collecting and modeling
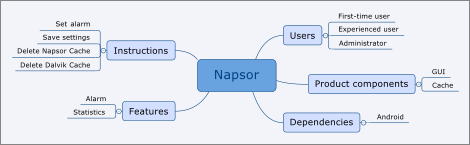
After I sit down at my desk, I start reading my emails. The product manager requests documentation for our new app "Napsor". Soon, we sit together for a first brainstorming session and collect information about all the important aspects of the app. What can it do? Who uses the app? What could the user want to do with it? Does the app have multiple components? During the meeting, I take notes and start filling a mind map. After the session, my mind map contains a variety of assorted key points (Image 1). These assorted key points subsequently form the structure of my new manual. But the mind map not only contains a rough structure of my manual. The mind map also contains important general concepts, for example, the app’s functions, the users, and the graphical interface. It describes the content-related domain "Napsor".
Identifying and recording
Knowledge managers work in a similar fashion. To develop a knowledge model, they first have to identify all important elements of a domain. But the outcome of their work is neither an information product nor a mind map. Knowledge managers create formalized descriptions of a domain. They describe the contents of my mind map in a standardized vocabulary. For their work, they use a large set of tools. The standardization committee W3C provides some of these tools.
W3C has defined various languages for knowledge modeling. Knowledge managers can use these languages as a standardized vocabulary. The most common vocabularies are RDF, RDFS, and OWL. While my mind map offers quick visual access to concepts of our domain, standardized knowledge models are machine-readable. For example, most major Internet search engines use standardized knowledge models to enrich their search results. Classes and instances
While developing a formalized knowledge model, knowledge managers look for patterns and similar elements in the large amount of information about their domain. Just like in my mind map, they group these elements. But grouping in a standardized knowledge model looks different than in the mind map. For example, in my mind map, the nodes "First-time user" and "Experienced user" form one group. I named this group "Users". In knowledge modeling, such groups correspond to classes. Classes group the elements of a domain. Members of a group share the same characteristics. The node "User" with its child nodes "First-time user" and "Experienced user" in my mind map corresponds to the class "User" and its subclasses "FirstTimeUser" and "ExperiencedUser" in OWL.
XML representation of classes "User" and "FirstTimeUser" in OWL:
<Declaration>
<Class IRI="#User" />
</Declaration>
<Declaration>
<Class IRI="#User" />
</Declaration>
<SubClassOf>
<Class IRI="#FirstTimeUser" />
<Class IRI="#User" />
</SubClassOf>
The more detailed a knowledge model is, the more classes and subclasses it contains. If the knowledge model is very detailed, then classes and their subclasses form a hierarchical structure. In this hierarchy, every class shares an "is-a" relation to the parent class. In our example, an "Experienced user" is also a "User"2.
My mind map contains not only abstract groups but also actual content. For example, there is a child node "Delete Napsor cache" under the "Instructions" node. The "Delete Napsor cache" node is not a sub-group but a member of the abstract group "Instructions". Knowledge modeling provides a vocabulary for cases like that as well. To assign a specific member to a class, the knowledge manager models the content element "Delete Napsor cache" as an instance of the class "Instructions". An instance is a member of one or more classes and shares their properties.
Classes and properties
After my meeting with the product manager, I get a cup of coffee and go back to my office. I have to start writing and the mind map has to help. It simply has to! So I turn on my computer and open my content management system. The mind map is a very basic tool for structuring content and presenting relevant domain knowledge. The content management system is more powerful. I can use it to write and manage text modules. Later, I will assemble and publish information products like manuals and HTML. And all the time, classes, subclasses, and instances are going to help me with my tasks.
If you write modularized documents frequently, then you have probably already grouped your modules by content classes and characteristics of the product. Established methods such as the PI classification help you model domain knowledge even without the knowledge of modeling languages3. For example, all my text modules containing safety warnings are instances of the class "Precautionary statement". The class "Precautionary statement" in turn is a subclass of "Note". According to class logic, all instances of the classes "Precautionary statement" and "Note" share some characteristics. They are all supplementary information and all look similar after publication. Properties and triples
Most content management systems provide another information layer for turning text modules into information products. Metadata characterizes content modules and indicates its relevance for certain target groups, products, or other variants. For example, my instruction "Delete Napsor Cache" is relevant for administrators. So I set the metadata attribute "Target group" to "Administrator". With this information, I can filter and define publication scenarios to generate manuals for administrators.
Metadata is every-day business for knowledge managers as well. In their knowledge models, they can use properties to add information to instances. In our example, the instruction "Delete Napsor Cache" has a property "is important for". The knowledge manager assigns the value "Administrator" to the property. However, the value is not merely a string of letters. In our knowledge model, "Administrator" is yet another subclass of "User". The property “is important for” links the instruction "Delete Napsor Cache" to a user from the class "Administrator". By linking, the knowledge manager establishes a relation between parts of the standardized domain model. The relation follows the pattern subject-predicate-object4.
"Delete Napsor Cache" – "is important for" – "Administrator" – this relation is a triple in knowledge modeling. All statements in a standardized knowledge model form such triples (Image 3). Knowledge managers obviously don't use just one property in their knowledge model – they use many. Knowledge managers can freely define properties to establish relations between classes and their instances. Because properties form triples, numerous connections between classes and instances create a network of subject-predicate-object relations.

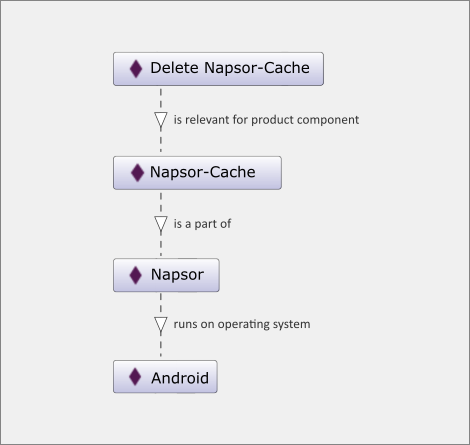
If I were to add all subject-predicate-object relations to my mind map, I would get a maze of nodes and lines. This is where the advantages of a standardized knowledge model come into play. The knowledge manager can query his knowledge model. The query software uses algorithms, so-called semantic reasoners. Reasoners infer even more triples from the network of explicitly defined relations. Using the query language SPARQL, the knowledge manager can then evaluate the defined and inferred triples. This makes simple queries possible, for example "Show me all the instructions that are important for administrators." But also complicated queries across several relations can be evaluated. My instruction "Delete Napsor Cache" has not only a property pointing to the class "Administrator". The instruction also has the property "is relevant for product component" with the value "Napsor Cache". "Napsor Cache" in turn has a property "is part of" pointing to "Napsor", and "Napsor" again has a property "runs with operating system" pointing to "Android". These relations form the following new triples:
"Delete Napsor Cache" – "is relevant for product component" – "Napsor Cache" "Napsor Cache" – "is part of" – "Napsor" "Napsor" – "runs with operating system" – "Android"
Based on these relations, I can infer that an administrator trying to delete the "Napsor Cache" needs to be familiar with Android. For this inferred statement, an algorithm works its way along the lines of the semantic network and collects all information modules that are relevant for the administrator. It then evaluates the relations between information modules, products, and their components. Finally, the relation from products to the required software is evaluated (Image 4).
While such query scenarios are possible even with conventional metadata models and intelligent website design – without a semantic model, they would require additional processing. Semantic technologies are designed precisely for such use cases. With more complex use cases, the required metadata can grow exponentially. Semantic knowledge models scales easily. A knowledge manager can simply expand the semantic network. A semantic content delivery portal then presents content that actually matters. Semantic content delivery portals
But how does this all concern me? After all, I am a technical communicator and not a knowledge manager. But things are not that simple. I write documentation but no one reads it. And my colleagues in the Support department are working overtime since the last Android update. There must be room for improvement. A content delivery portal may offer the desired solution. Content delivery portals are supposed to provide users with relevant information. To do so, they use metadata and an underlying knowledge model. How could such a solution look like?
Since semantic networks are easy to expand, knowledge managers can link knowledge models from different domains. By linking domains, they can also integrate data from different sources. For our problem, we link the ticket system of the Support department with the documentation website. This expands our knowledge model. We define a new class “Event” and its subclass "Firmware Update". We then link "Firmware Update" with "Napsor Cache" using a new property. The result is the following triple: "Firmware Update" – "changes product component" – "Napsor Cache".
Customer support uses its own knowledge model. It has the class "Firmware Update" as well. However, here it is a subclass of "Ticket Category". The knowledge manager now establishes a relation between both "Firmware Update" classes. That generates an indirect linking of the tickets to our content (Image 5).
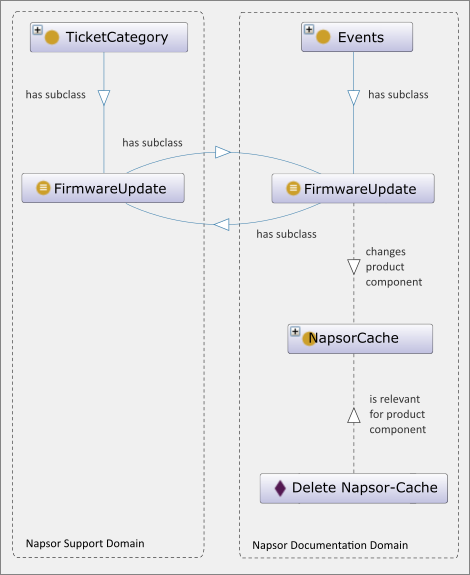
Since the linking is depicted in our knowledge model, as the technical communicator, I need not add any more metadata to the instruction. The semantic network automatically establishes a relation between my instruction and the event As the linking is added to our knowledge model, I don’t have to add more metadata to my content. Less work for technical communicators, maybe another coffee then! While I get my refill, the semantic network automatically establishes a relation between my instruction and the event “Firmware Update”. After exporting the ticket data as semantic triples from the ticket system, the content delivery portal integrates the export into its existing knowledge network of the "Napsor" domain. Next time my colleague from Customer support logs into our documentation website, the content delivery portal lists documentation that is relevant for his ticket. The content delivery portal takes into account user roles and their current work packages and provides relevant information for each user.
As a technical communicator, this semantic technology relieves me of some cumbersome tasks. For example, I no longer have to maintain lists of links to related topics. Content delivery portals can generate these links by querying the underlying semantic web. But nothing is for free, of course. For a content delivery portal to return meaningful results, we need to harmonize the metadata. All departments that want to integrate their data into the content delivery portal, have to develop a semantic metadata model. But those who invest into this new technology can deliver meaningful information to the users of their manuals. And this is what turns even a technical communicator into a true knowledge manager.
RDF, RDFS and OWL
The World Wide Web Consortium W3C develops standards for describing metadata. The three most popular ones are RDF, RDFS, and OWL. The standards build upon each other and differ with respect to vocabulary size.
RDF – the Resource Description Framework RDF is a data model with formal semantics. It is an essential part of the Semantic Web5. RDF provides a basic vocabulary for modeling statements about resources. Statements are modeled as triples. A triple comprises three components: subject, predicate, and object.
RDF can be serialized in multiple ways. One serialization is RDF/XML. A more compact form of serialization is Turtle. Turtle is easily readable and widely used. The following example shows a subject-predicate-object relation in Turtle:
my:Napsor rdf:type my:AndroidApplication .
RDFS – RDF Schema (RDFS) is a semantic extension of RDF. RDFS formalizes simple ontologies. RDFS provides a vocabulary for modeling application domains. For example, it extends RDF by adding classes and subclasses. It also adds expressions to define the subject and object of a property. All in all, RDFS allows more complex domain descriptions6.
The semantics of the RDFS elements group resources with the same properties to form a classification system, so that subclasses and sub-properties are subsets of their parent class and their parent properties. The following example shows the class-subclass relation in Turtle:
my:User rdf:type rdfs:Class .
my:FirstTimeUser rdf:type rdfs:Class ; rdfs:subClassOf my:User .
A semantic application can process these relations and infer further statements about the resources. What’s true for the parent class is also true for the subclass.
OWL – Web Ontology Language OWL is also a W3C specification and is technically based on RDF. OWL is more expressive than RDFS. For example, OWL can model constraints for classes and special relations between properties7. The following example shows an inverse relation in Turtle:
my:IsPartOf rdf:type rdf:Property . myhasPart rdf:type rdfs:Property ;
owl:inverseOf my:IsPartOf .
However, increased expressive power poses a problem. Knowledge models that use the full OWL vocabulary can be inherently contradictory. Algorithms can no longer make unambiguous evaluations. Algorithms would have to weigh statements to resolve these contradictions. To deal with this problem, the W3C defined a subset of OWL. The subset OWL DL uses only parts of the OWL vocabulary. As a result, reasoners can interpret the vocabulary of OWL DL without ambiguity problems.
Hierarchy and networks
In knowledge modeling, everyone can say anything about everything. This open world assumption of the semantic web leads to a diversity of knowledge models.
Despite this diversity, there are some recurring patterns. Frequently recurring structures in knowledge models are hierarchies, taxonomies, and ontologies.
Hierarchies
In knowledge modeling, elements often form a structure of superior and subordinate. Some elements stand above other elements. A tree structure is created when every element has only one element immediately above it. This is what knowledge managers call mono-hierarchy. If some elements have several superior elements, then the structure is a poly-hierarchy. Both structures classify objects by dividing them into groups and arranging them in a hierarchy. From top to bottom, the grouping rules increase in complexity and go from generic to specific.
Taxonomies
Taxonomies are mono-hierarchically structured classifications: every class has only one class immediately above it. The entire classification forms a tree structure. The closer to the root, the more general is the information about an element. If an element is positioned deep down on a branch, then the knowledge model provides very specific information about the element. Such a hierarchical classification of knowledge provides simple semantics for its domain. In technical communication, the term taxonomy is often used for a classification system with almost no semantics. Examples of classifications are the sorting of metadata and semantic storage structures.
What does taxonomy not do? Taxonomies do not sort objects and their parts. In taxonomies, a member of a subordinate group is also a member of the superior group. The subordinate element stands in a "is-a" relation to the superior element. For example, a hare is a mammal. A hare’s foot on the other hand is neither a hare nor a mammal.
Ontologies
If further semantic relations connect elements of a hierarchy, then these relations form a network or semantic web. These networks are called ontologies.
The elements of an ontology are grouped into classes and subclasses. The classes in turn have members. The members are called instances. An instance is a specific manifestation of a class. Properties describe logical relations between classes and instances. The properties are inherited. For example, if a class "User" has the property "has username", then the subclass "FirstTimeUser" also has this property. To model ontologies, knowledge managers often use standardized formal languages such as RDF Schema and OWL. Ontologies that are modeled in standardized languages are machine-readable and can be queried using the query language SPARQL. The following example in SPARQL lists all operating systems that are relevant for the instruction "Delete Napsor cache":
SELECT ?os
WHERE {my:DeleteNapsorCache my:isRelevantForProductComponent ?prodcomp .
?prodcomp my:isPartOf ?prod .
?prod my:runsOnOperatingSystem ?os. }
Links and literature
1 Nonaka, Ikujiro; Takeuchi, Hirotaka (1995): The knowledge creating company: How Japanese companies create the dynamics of innovation. Oxford University Press: New York.
2 Sowa, John F. (2000): Knowledge Representation: Logical, Philosophical, and Computational Foundations. Brooks Cole Publishing Co.: Pacific Grove.
3 Ziegler, Wolfgang (2014): PI ist Klasse! Einsatz und Nutzen von (PI)-Klassifikationen für die modulare Informationserfassung (PI is class! Application and benefits of (PI) classifications for modular information acquisition). tekom annual meeting, Stuttgart.
4 Semantic Web Best Practices and Deployment Working Group (2005): Representing Classes As Property Values on the Semantic Web: W3C Working Group Note 5 April 2005.
5 RDF Working Group (2014): RDF 1.1 Primer: W3C Working Group Note 24 June 2014.
6 RDFS Working Group (2014): RDF Schema 1.1: W3C Recommendation 25 February 2014.
7 OWL Working Group (2012): OWL 2 Web Ontology Language Primer (Second Edition): W3C Recommendation 11 December 2012.
For further reading
- Allemang, Dean; Hendler, Jim (2011): Semantic Web for the Working Ontologist: Effective Modelling in RDFS and OWL. Morgan Kaufmann, Waltham 2011, 2nd Edition.