Driving technical documentation from a digital twin
What is a digital twin?
The digital twin of a technical product is a virtual model that represents the product with its components and functions. Once the product goes into operation, the digital twin can use data from sensors, simulations, and algorithms to support behavior analysis, predictions, and optimization throughout the product’s entire life cycle. As a result, it is possible to detect malfunctions at an early stage, plan predictive maintenance work, and draw conclusions about product development.
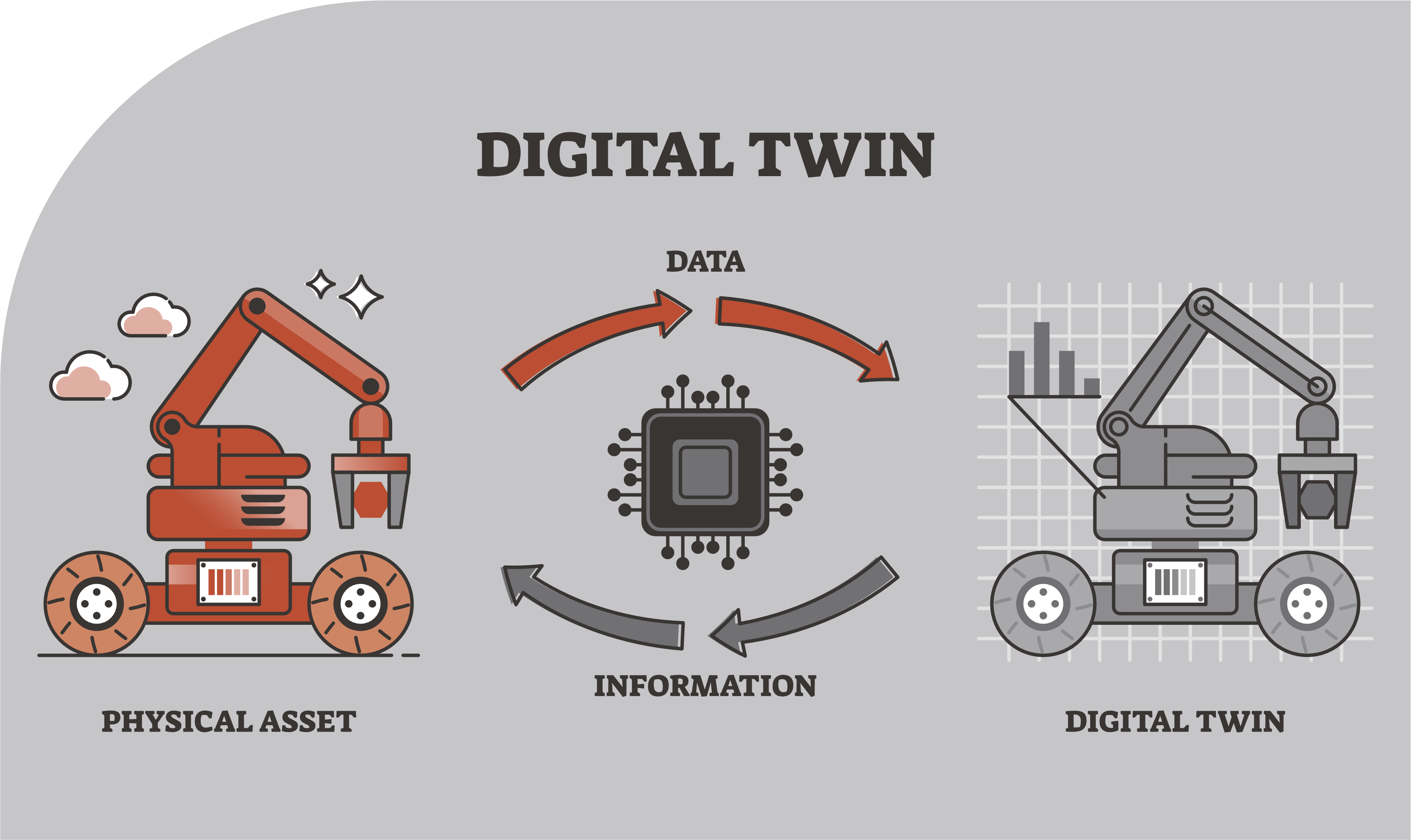
Technical documentation and the digital twin
A product’s digital twin reflects its exact configuration. For the technical documentation to match the product, it must be written and delivered product-specific and cannot cover several different product variants. But how is this product-specific documentation created and what do the authoring processes have to look like?
This article describes how the company Endress+Hauser has developed a technical solution to meet the challenges of product-specific documentation for the digital twin.
The article is based on the presentation by Endress+Hauser and parson that Thomas Ziesing and Ulrike Parson held together at the tcworld conference 2024.
Background and motivation
The project is part of an iiRDS pilot project sponsored by the iiRDS consortium. Its goal is to create, manage, and deliver technical documentation using product data and iiRDS metadata
Product-driven documentation at Endress+Hauser
Endress+Hauser is a leading company in process and laboratory measurement technology and automation solutions. The company has adopted product data driven documentation. Product data from SAP, PIM, and software configuration systems are linked to a technical documentation information model using a knowledge graph. This means that the content of the technical documentation is precisely tailored to the respective product configuration.
As a service provider for smart content and intelligent information solutions, parson is supporting the development of the information architecture and the implementation of the knowledge graph solution.
The knowledge graph platform used is Product Content Connect by Empolis.
Challenges and regulatory obligations
Endress+Hauser faces the challenge of accompanying highly configurable products efficiently with relevant and contextual information. New regulatory obligations such as the VDI 2770 or the Machinery Regulation and new output formats – from electronic documents to multimedia content – require innovative approaches for the information delivery.
New delivery forms for technical documentation
Users increasingly expect relevant information to be provided directly instead of having to laboriously search for it. This requires new forms of delivery, for example through apps or AI-based applications.
The digital twin and associated sub-models for the asset administration shell of the Industrial Digital Twin Association (IDTA), especially "Handover Documentation (PDF)" and "Intelligent Information for Use (PDF)", make it possible to deliver configuration-specific documentation. The goal is to tailor the amount of information specifically to the product variant in question and thus guarantee a more efficient use.
Project goals: Documentation matching the product configuration
Technical documentation can be created, managed, and delivered in line with the product configuration and enriched with iiRDS metadata. This makes the following possible:
- Provide information tailored to specific configurations
- Reduce redundancies and sources of error
- Improve usability for both customers and support teams
Reusable information units can be used selectively by structuring the content in a modular way.
The aim is to provide customers with the precise information that is relevant to their specific product variant.
Technical implementation
The solution to the technical implementation of the project at Endress+Hauser lies in core key components:
1) Knowledge graph
The knowledge graph is the key component that stores data models and information models as well as product data.
The knowledge graph platform works as a semantic middleware and imports product data from the original data sources (sources of truth).
Relations mark product variants as relevant for the documentation, meaning that the product model can be linked to the iiRDS-based information model.
The knowledge graph can then identify the documentation requirements for a specific product configuration and compile the corresponding content as structured information (topics).
This combination takes place before the technical writers start to create or edit the content in the authoring system. They receive a documentation project (the so-called authoring job) from the knowledge graph that matches the product configuration. All information units are already filled with the necessary product metadata and information metadata.
2) Data sources (sources of truth)
Various company sources feed the knowledge graph with data, including a PIM (product information management), an ERP system (SAP), or the software configuration.
These sources provide product properties, features, order configurations, software features, and user interface names (UI strings).
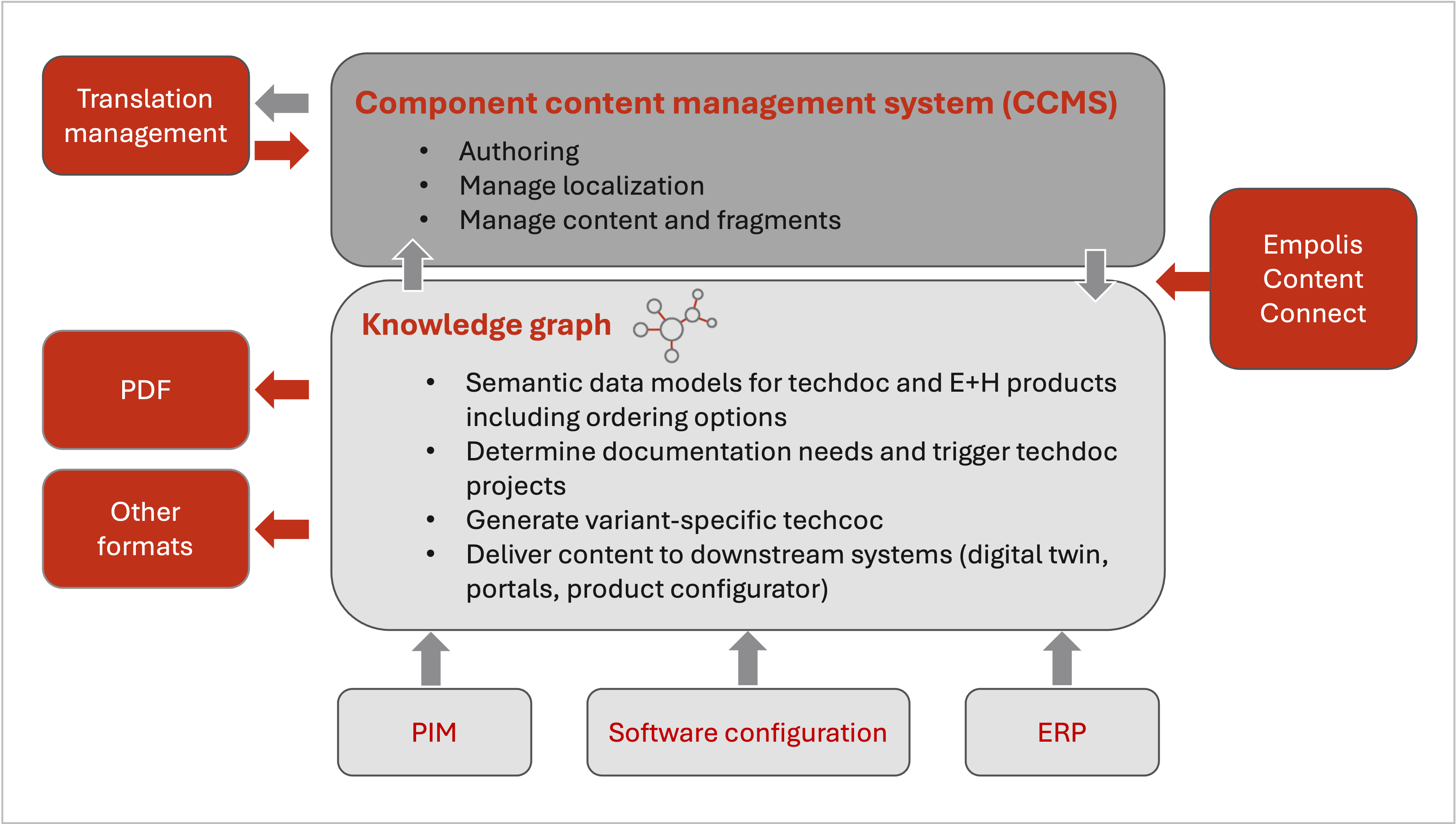
3) Authoring system
The DITA authoring system (CLS by Empolis) generates content, saves fragments for reuse, manages workflows, and controls the translation management.
The knowledge graph ensures that all necessary metadata for an authoring job is provided.

The technical writers use the Oxygen Author by Syncrosoft to edit technical documentation content. Within the authoring system CLS, the technical writers can also use additional features by Oxygen, for example searching for reusable fragments via metadata.
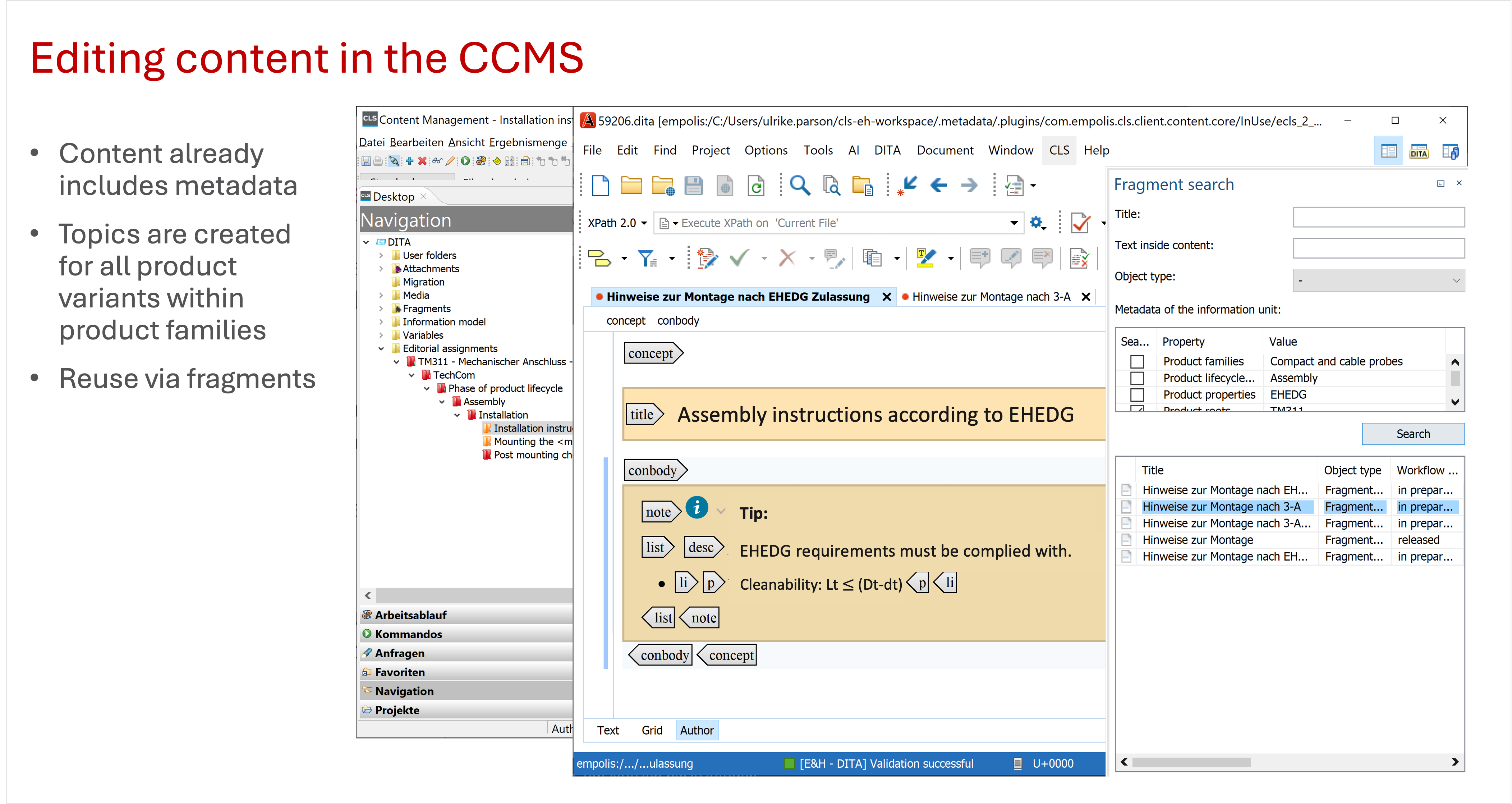
How is technical documentation created – the process
- Once the product structure is available, for example in the PIM, documenting work can begin. New product structures are regularly imported into the knowledge graph and can be used for authoring jobs.
- The task manager creates the authoring job. The job includes a product configuration and a selection from the information model, for example all nodes for getting the product started.
- The knowledge graph checks for product properties relevant to the documentation and identifies which information units (topics) are required for the product configuration.
- The authoring job is sent to the authoring system. Technical writers and translators work on the jobs within the authoring system.
- The output of various formats such as PDF, iiRDS packages, etc. is carried out via the knowledge graph.
How variant management works
The knowledge graph also controls the variants of the product documentation. The variant selection as a central mechanism links the product model to the information model. An example of how this works:
- A product with a hygiene certification requires specific installation instructions.
- The information architect creates a “Hygiene requirements” variant selection and links this to the “Assembly instructions” node in the information model. The product properties for the hygiene certification are combined in the variant selection.
- If an authoring job includes the installation instructions and concerns a product with a hygiene certification, an additional topic, a documentation variant, is created for this node of the information model. If the topic already exists, it is added to the authoring job.
This automatically creates variant-specific documentation without authors having to manually check each individual case.
The role of technical writers
Technical writers no longer write document-based but rather receive the authoring jobs with enriched metadata. Their tasks include:
- Editing authoring jobs: These are already tagged with complete metadata. The metadata includes product family, product life cycle phase, topic type, and other relevant information.
- Creating and editing content: The technical writers create content, save fragments for reuse, and reuse these fragments. They work with variables and can find and use existing topics and fragments in the system.
- Standardizing content: They work on standardizing content across all technical writing teams of the Endress+Hauser group, which poses a considerable challenge.
- Working with the knowledge graph: The authoring system combined with the knowledge graph saves the topics and fragments and reports back which information is already available. This enables reuse and prevents duplicate work.
- Managing translations: The system also is linked to the translation management system, meaning that the translation managers can have the content be translated into various languages.
- Optimizing review processes: A web-based review process for the technical review by subject matter experts makes it possible to continuously review individual information units (topics). Consequently, the documentation is not only reviewed when it is complete, but as an ongoing process.
The role of information architects
Information architects have an essential role in this project. Their tasks include:
- Combining the product model with the information model: They create the link between the product data and the information model. This includes identifying the variant-defining characteristics of the product classification.
- Checking attributes: They verify some of the attributes in the PIM (Product Information Management system) to ensure that the data is correct and complete.
- Standardizing the information model: They are responsible for restructuring the technical documentation: away from documents, towards topics. This is necessary for meeting the new project requirements.
These tasks are crucial for successfully finalizing a project and reaching the defined goals.
Challenges
The project involves both technical and organizational challenges:
- State of the source data: Data from various systems with different levels of quality and granularity must be harmonized.
- Consistency of data models: Metadata and classification concepts must be aligned and harmonized.
- Dependency on product data: Technical documentation can only be created once the product data is available. This means that for new products that are still in development, data sets must also be created early in the PIM or other product data systems.
- New roles in technical writing: New roles exist, for example for information architecture.
- Switch from documents to topics: Content must be broken down granularly. This means that existing documents must be restructured completely.
Further outlook
The solution used by Endress+Hauser offers great potential to further automate and digitize technical communication and other processes in the company.
Automatically create content
The information in the knowledge graph can be used for automatically creating technical documents, e.g. data sheets. Integrating additional company systems will further increase efficiency.
Use of AI-based analysis and optimization procedures
AI can help identify reusable content and optimize content.
Central data hub and further integrations
A central data platform enables technical information to be seamlessly connected with other company departments. This would allow content from the technical documentation to be integrated, for example, into service and maintenance applications.
Use of chatbots and voice-controlled assistance systems
Modularized documentation can be the basis for intelligent assistance systems that provide users with quick and precise answers to questions relating to their use of the product.
Sustainability and digital compliance
Digitizing technical documentation significantly reduces paper consumption and printing costs. In addition, compliance with regulatory standards can be improved through centralized and traceable information management.
These developments show how the digital transformation of technical documentation is only just beginning. The potential offered by automation and digital twins is tremendous
Conclusion
Digital twins are revolutionizing technical documentation by incorporating product configuration-specific content. Despite challenges regarding data integration and organizational transformation, this approach offers significant advantages:
- Increased efficiency through automation
- Greater modularization for better reuse
- More accurate, variant-specific documentation
- Optimization of the entire information flow in the company
The project shows how companies can use digital technologies to prepare themselves for the future and make technical communication more efficient.
Related content
Video recording of the presentation (in German, English subtitles available):
Project references
- Information architecture and consulting for content management and content delivery in technical communication
- Reshaping technical communication towards content delivery
parson services
- Develop a content strategy for your company
- Metadata models for smart technical communication
- Invest in smart content and iiRDS
- Component content management systems (CCMS) for technical documentation
- DITA-XML for technical documentation
- What we do for you as a reseller of Oxygen products