How to feed a chatbot with your documentation content
Zugehörige Leistung: Chatbots im Kundenservice
The goal of my master’s thesis was to research whether chatbots as a user assistance could be made accessible for technical documentation content, and to which end chatbots can be used for product support, more specifically for troubleshooting for technical documentation.
By working with BOTfriends as a chatbot framework supplier, RWS for the DITA-based Component Content Management System (CCMS) and Content Delivery (CDS), and parson for test data and DITA expertise, I managed to set up and program a working chatbot which would effectively help people solve technical issues. Flensburg University of Applied Sciences supervised the thesis and offered valuable support, especially during the usability tests.
Not much research has been done on user satisfaction when interacting with chatbots. I therefore developed a questionnaire for this work. It assessed the user satisfaction with the chatbot, using three troubleshooting scenarios to explore the extent to which users would accept a chatbot for technical documentation content.
Technical background
DITA, the OASIS Open Darwin Information Typing Architecture, is a standard XML-based architecture, or file type, for documentation content. DITA features content modularity, content reuse, and controlled extension of document vocabularies and is designed primarily for technical documentation. DITA is based on XML vocabulary, but its base vocabulary is modelled closely on HTML. I used DITA documentation content as the basis for my chatbot.
I explain technical terms in the glossary at the end of this article.
Chatbots
The first chatbot was invented in 1966, long before computer programs became publicly available, although it was not called “chatbot” at the time, but simply ELIZA1. Today, chatbots go by many names: Chatbot, virtual agent, scriptbot, FAQbot, and voicebot are only some of the names used to describe the functionality these bots offer. The term “chatbot” itself is a neologism, a contraction of the terms “to chat” and “robot”2. Chatbots are robots that you can chat with. Likewise, an FAQbot is a bot that answers FAQs, frequently asked questions; and a voicebot is a bot that uses a speech dialog system. All these bots have the same underlying function of natural conversations with computers. The process of how a (chat-)bot works is rather simple:
A user enters a text in natural language (that is, human speech in contrast to artificial languages such as computer programming languages), which the computer then parses and translates into an action it can carry out 2, i.e., answering a user’s question. ELIZA was the very first rule-based chatbot. Weizenbaum explained how ELIZA works as follows: “The chatbot reads the text and inspects it for the presence of a keyword. If such a keyword is found, the sentence is parsed according to a rule associated with the keyword, if not, a content-free remark is retrieved. The text so computed or retrieved is then printed out”.2
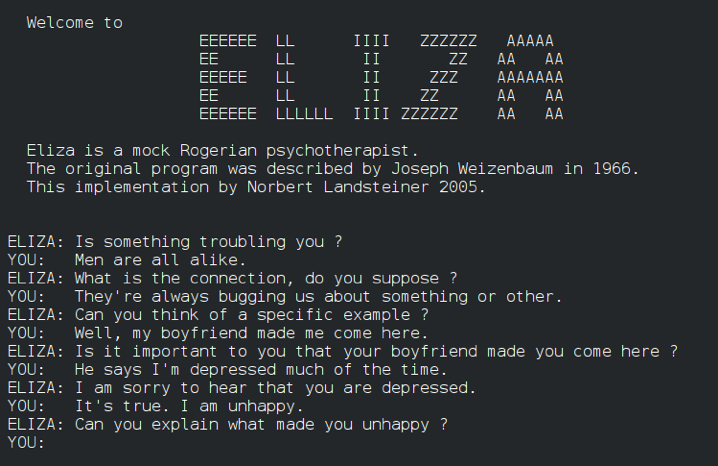
Rule-based Chatbots
Rule-based chatbots extract the meaning of a sentence or an utterance by identifying keywords, often sorting the most appropriate response by keyword density. They then can reply to the queries identified by the keywords with answers that have been pre-written by the chatbot’s developers. Scenarios for which the chatbot has pre-programmed responses therefore work well with rule-based chatbots. However, they cannot answer queries beyond those they have had defined. They therefore work well in small, more limited scenarios such as booking processes.
The key aspect of rule-based chatbots is that they follow pre-defined rules to respond to detected keywords. The possible conversations that a rule-based chatbot could have with users are mapped in decision trees or other charts, which means that all the chatbot’s reactions can be predicted.
Machine Learning-based Chatbots
By contrast, a second approach to chatbots utilizes Artificial Intelligence (AI), which is generally seen as the more sophisticated approach of the two3. This approach is realized by ‘teaching’ the computer to understand human language using Natural Language Processing (NLP) and interpret what has been said2. NLP describes a set of techniques used to convert passages of written text into interpretable datasets that can be analyzed by statistical and machine learning models.4
Simply put, AI takes written language, converts it into machine-readable data sets and then builds statistical models of how language works. For example, if the answer to “Are you hungry?” in hundred different scenarios is always “Yes”, the AI learns that the answer to that question is always “Yes” and will respond accordingly when asked itself. If no other answer is available to the chatbot when learning, it will assume that “Yes” is the correct answer with 100% confidence. The response is then calculated and returned as the correct answer. If the answer “Yes” is then always accepted by users as the correct or appropriate language usage, later models will continue to return this response with 100% confidence.
It gets more complicated when there are many different possible replies, i.e. “Yes, I am hungry”, “No”, or even something only vaguely related such as “Let’s get pizza”. Because there are so many different possible responses in human language, language models have to be trained extremely well and over a long period of time to ensure that the AI using the models can answer anything with a certain degree of confidence. The data sets required for language models to work well are consequently gigantic, making them harder to obtain.
In the last few months, ChatGPT has become the probably most popular language model for AI-based chatbots. Its brilliance lies in its ability to converse on almost any topic while being able to change register, making it sound human-like as it returns sensible answers in appropriate language. ChatGPT’s ‘knowledge’ comes from the vast amount of data used to train this language model. However, this is also its greatest liability: Any input given to ChatGPT is used to train later models, meaning that any data given to it can and will be indirectly made available to anyone in later versions. At the time of writing this article, ChatGPT 3.5 was free to use and the latest, most useful version available. Whilst working on the thesis, the company behind ChatGPT, OpenAI, already released version 4.0 which was additionally trained with data it had acquired from users interacting with ChatGPT 3.5. This has improved the quality of ChatGPT even more. However, it also means that any data given to ChatGPT is – indirectly – publicly available. This raises privacy concerns and makes it unusable for many legal or business purposes.
Machine Learning-based chatbots are better suited for scenarios where the conversation flow cannot be clearly mapped or where the scope is too extensive for a rule-based chatbot to manage. A scope can be considered too large either in the sense of language when the user input cannot be semantically constrained and many different input terms are possible for a topic; or the scope can be too large topic-wise if there is no limit on what the chatbot should be able to understand. In both cases, AI-powered chatbots work more flexibly due to their ability to understand human language, thus can have real conversations. Because the responses are not predefined, AI-based chatbots are better suited for creative tasks, such as writing assignments, than responses that require current, factual knowledge. They also perform better in speech in long-term projects because it takes time to train and perfect the language models, but then they have an advantage in communication over rule-based chatbots as they sound more natural. Even so, because they calculate – cynics might say ‘guess’ – the best-suited response rather than providing a predefined, factually correct response specified, AI-based chatbots might not be the preferred approach even for long-term projects or use cases.
Although Machine Learning is often regarded as the more sophisticated and consequently better approach to chatbots3, both Machine Learning and rule-based approaches are valid. Depending on circumstances such as time, finances and budget, and complexity of the requirements, one approach might make more sense or be more suitable than the other, yet one cannot say one approach is generally superior to the other. This should be kept in mind when considering how to set up a chatbot.
Setting up the chatbot
To set up my chatbot I had to incorporate various technologies and work with several partners who provided access to technologies or offered other support. The partners involved had individual requirements, some conceptual and some technological. Each partner provided valuable help in working with the specific tools. The results of this thesis are aided by the collaboration between the parson AG, who officially supervised my thesis; RWS, a content and language technology and service provider; and BOTfriends, a company for sophisticated chatbots and voice assistants. All parties are also listed below this article, explaining their involvement in more detail.
For the chatbot, I set up a web server. This web server was able to read files from their file location using an XML parser. The files I used for the chatbot were parson test data, DITA topics for troubleshooting with a pizza oven. I then connected the BOTfriends development platform, Botfriends X, to the web server. BOTfriends offers a simple integration via webhooks. So this connection could be established by simply adding the webhook’s URL to BOTfriends X and a secret Json Web Token to the web server. The secret Json Web Token authenticates the requests sent with all messages from BOTfriends X.
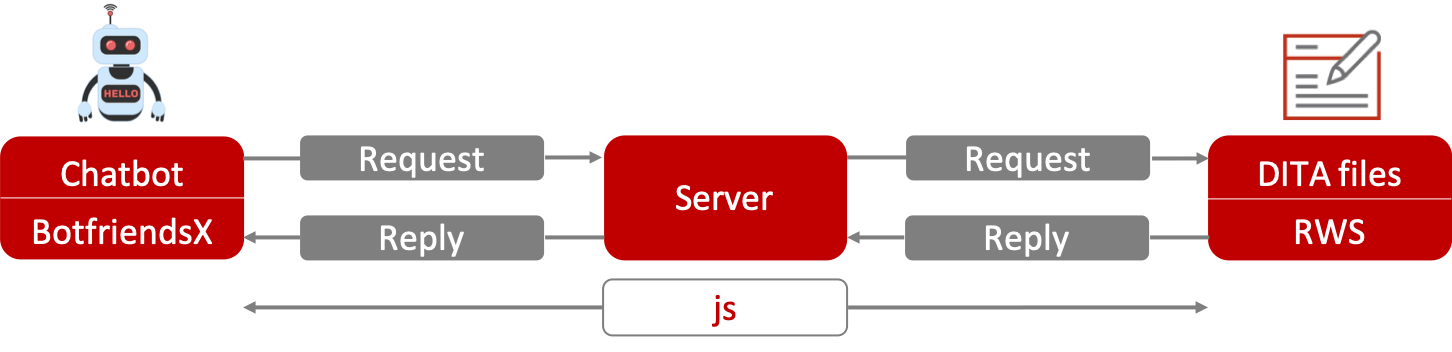
I set up the chatbot in the BOTfriends X environment by adding the possible problem cases (the symptoms described in the troubleshooting files) as intents. For each intent, several example utterances were added. However, I did not define the response in the environment itself as the response was supposed to be extracted from the troubleshooting files. Instead, I defined an action telling the chatbot that if the utterance to an intent was detected, then the action “get.troubleshooting” should be triggered. Calling this action would then trigger the request to the web server, which would read the correct answer from the troubleshooting file. This was accomplished by reading the troubleshooting file with all the symptoms, causes, and remedies labelled in it and returning the causes and remedies that match the symptom detected in the intent.
For better understanding, an exemplary chat is shown. The dark blue messages on the right-hand side are exemplary utterances from a user. The chatbot responses are on the left-hand side.
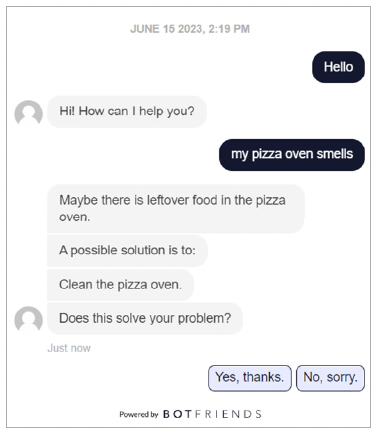
In the figure, the chatbot reads the keywords “oven” and “smells” and therefore reads the solution(s) from the DITA file Troubleshooting_Oven_Smells. The chatbot returns the possible cause and a remedy in individual messages. It then asks for feedback with a quick-reply element. The buttons with the answer options appear in light blue to distinguish them from the user’s previous chat messages.
This solution is more sophisticated than hardcoding the response because it returns the answers more flexibly. However, a previous project, the [iiBOT](https://www.parson-europe.com/en/blog/iibot-gives-instructions) had already achieved this level of flexibility. So the next step to a higher level of sophistication was to make the chatbot understand contexts. Contexts are used to store the state of a conversation and the information the user has provided to the bot and can thus be used to chain intents to form a dialog5.
The web server handles the intents sent by BOTfriends X via the BOTfriends-x-sdk package. This defines what the intent looks like, meaning that it is defined as an object with certain attributes: An intent contains the detected action, recipient, output (including the new text messages), intentID, and the context. This means that a chatbot can understand when user utterances refer or relate to previous messages: Contexts are key-value pairs that contain both the current symptom and the last remedy provided. Therefore, a new context is established when a new problem scenario is mentioned and the respective troubleshooting topic that matches the described symptom is run.
After updating the intent with the response chat messages and the updated context, it is sent back to BOTfriends X in an HTTP response. The updated context is provided by BOTfriends X in the user’s next intent to continue the conversation, thus circling back to the context being read. With this implementation, the chatbot is able to help users with any troubleshooting scenario that has been saved as an intent.
The first part of my thesis was to understand how DITA and chatbots in general work before setting up a proprietary chatbot and its communication with the backend technologies. Once the technical setup was complete, the next step was to analyze how well the chatbot worked.
Benefits of this approach
The main benefits of this approach can be summarized as controlled flexibility: On the one hand, it is flexible because the responses are not hardcoded but dynamically returned from the DITA content. This means that if something changes within the content, the chatbot always returns the current version with the changes automatically without having to update the intent.
On the other hand, the responses are controlled as they are returned from within the approved and released content. Unlike ChatGPT or other AI language models, my chatbot does not calculate – or guess – the causes and remedies but reads them from the content repository. This means that the chatbot only suggests the solutions approved by the authors of the content. The data set is therefore controlled, which also means that only limited training of the chatbot is required. Also, thanks to [metadata](https://www.parson-europe.com/en/knowledge-base/first-comes-medadata-then-comes-content-how-control-your-ccms-metadata) for intent descriptions, the chatbot can understand versioning, which means it will only return solutions that work for the specific model in question.
Usability test and questionnaire
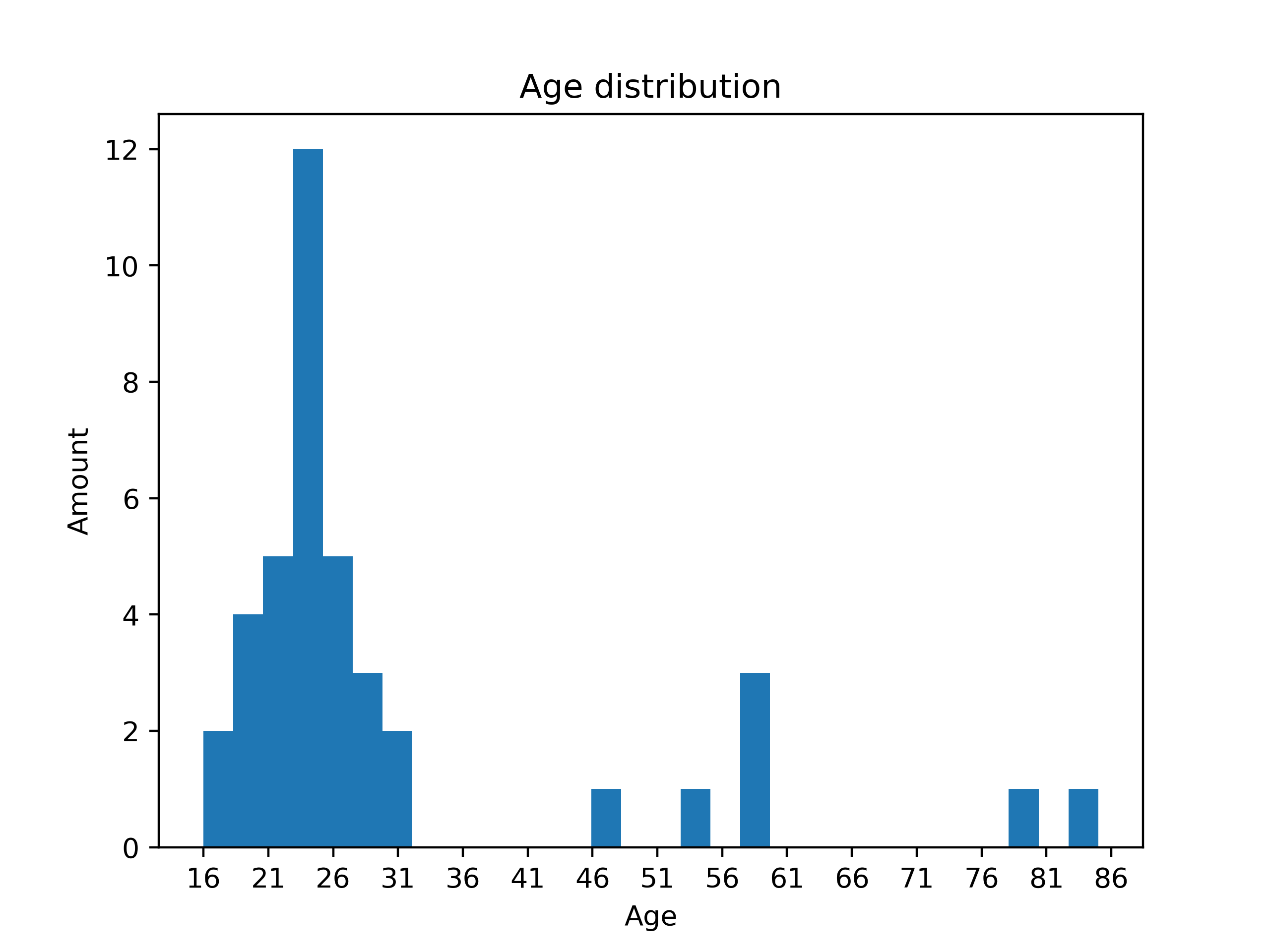
Currently, there are only a few related studies and none that addresses the exact research hypotheses of my work. To evaluate the chatbot’s performance, I conducted a usability test with an accompanying questionnaire. Participants were asked to test the chatbot in three test scenarios regarding a broken pizza oven. A total of 40 people from Germany participated in the test. By asking co-workers at parson, friends, friends of friends, and family members, I was able to survey a group as heterogeneous as possible. The chatbot was tested by 20 men and 20 women. The average age of the men was 28, and the average age of the women was 34. The youngest participant was 16; the oldest participant was 85. Most participants were in their twenties, some in their thirties, and several in their fifties. The mean age was 25.
Regardless of age, many participants were apprehensive when asked to test a chatbot, stating that they were not comfortable with technology or did not know what a chatbot was. Accordingly, 27 of the 40 participants (67.5%) said they had previous experience with chatbots, while the remaining 13 participants (32.5%) said they had never knowingly interacted with chatbots before, as shown below.
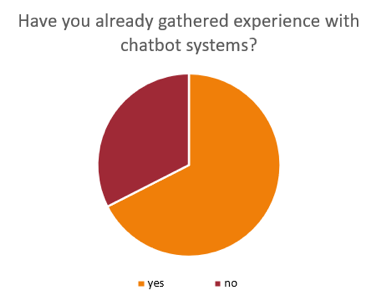
The overwhelming majority of the participants with chatbot experience listed chatbot systems that they had perceived poorly. Despite their initial concerns about working with chatbots, however, almost all participants rated the interaction with my chatbot as positive:
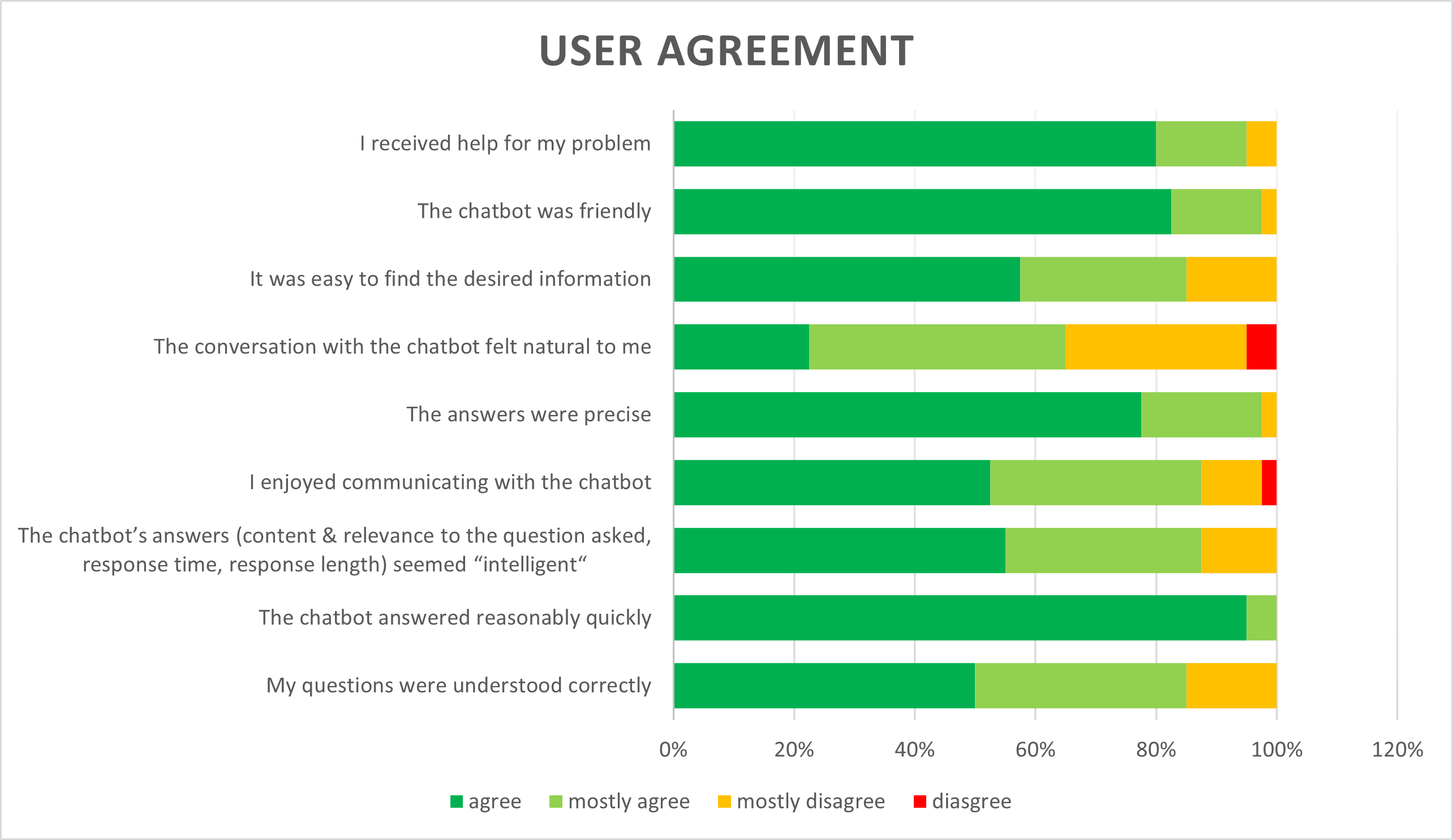
The image shows which percentage of participants agreed with the statements on the left to which degree.The statements that participants were supposed to rate are listed on the left and the distribution of the answers are to the right. Positive agreements are shown in green shades (“agree” and “mostly agree”, negative agreement in orange and red (“mostly disagree” and “disagree”). At first glance, you can see that most participants agreed with the statements, rating them positively. Accordingly, 36 of the 40 participants (90%) stated that the chatbot had helped them in the test scenarios.
Conclusion
The goal of my work was to make documentation content available to chatbots and to evaluate the user satisfaction with such a bot. For this, a chatbot was set up using components provided by several partners. The chatbot can dynamically access DITA troubleshooting topics and return the correct solutions to troubleshooting scenarios without having to save the solutions as responses. 40 participants were asked to test the chatbot by solving three troubleshooting scenarios and rating their satisfaction with the interaction with the chatbot. The overwhelming majority of participants rated their user experience positively, stating that they enjoyed using the chatbot, that it had helped them solve their problems and that using chatbots to access technical documentation content seemed useful. In general, despite the previous negative bias towards chatbots, almost all participants rated the usability positively. All in all, this shows that it is not only possible but also useful to make technical documentation content accessible to users via chatbots.
Outlook
I will be explaining the technical set-up more thoroughly at both the tcworld conference (14.11.2023, 09.00 am in Stuttgart) and in a webinar with RWS. For both, I will also talk about the usability and user satisfaction in more detail.
Glossary
Artificial Intelligence (AI
Computers’ capability to learn
BOTfriends X
Development platform for chatbots
Chatbot
Computer program humans can converse with
Context
For chatbots, a scenario for replies
DITA (Darwin Information Typing Architecture
Topic-based file format for documentation content
Intent
What a user means to say or achieve with chatbots
Keyword
Words that sum up the intent in an utterance
Machine Learning (ML)
Statistical models built on machine-readable datasets
Metadata
Information on information, e.g., title or author
Natural Language Processing (NLP)
Turns written text into machine-readable datasets for computers
Quick reply
Clickable pre-determined responses for a chatbot
Rule-based
One way chatbots work by following set rules for the conversation
Usability test
Tests for product on how easily they work
Utterance
For chatbots, a user’s input
Webhook
In web development, a method of augmenting or altering the behavior of a web page or web application with custom callbacks
Web server
The server used to send the files to BOTfriends X
List of partners
- BOTfriends were generous enough to supply me with a chatbot free of charge.
- RWS provided Tridion - a DITA-based Component Content Management System (CCMS) with dynamic Content Delivery (CDS) - in a Software-as-a-Service mode along with valuable technical support (https://www.rws.com/)
- parson provided test data and DITA expertise (https://parson-europe.com)
-
Flensburg University of Applied Sciences supervised the thesis and offered valuable support, especially during the usability tests.
Footnotes
1 Weizenbaum, J. (1966): “Computational Linguistics. ELIZA – A Computer Program For the Study of Natural Language Communication Between Man And Machine”, in: Communications of the ACM, Volume 9/Number 1, pp. 36–42. MIT, Cambridge.
2 Skodowski, M. (n.d.): “Chatbot”, in: BOTwiki – The Chatbot Wiki. Retrieved from: https://botfriends.de/en/blog/botwiki/chatbot/ [last access: 15.06.2023]
3 knowhere GmbH (2021): “Was ist ein Chatbot?“, in: {moin}ai. Retrieved from: https://www.moin.ai/was-ist-ein-chatbot [last access: 14.06.2023]
4 Harrison, C. J. and Sidey-Gibbons, C. J. (2021): “Machine learning in medicine: a practical introduction to natural language processing”, in: BMC Medical Research Methodology, Volume 21/Number 1, p. 158. Retrieved from: https://doi.org/10.1186/s12874-021-01347-1 [last access: 18.06.2023]
5 BOTfriends GmbH (2023): BOTfriends. Retrieved from: https://botfriends.de/en/ [last access: 09.06.2023]