Good riddance to the manual. From documents to knowledge bases
Corresponding service: Self-service applications
Usually, we create technical documentation in the form of a manual – for specific target groups and product versions. With the help of content management systems, we add metadata to our text modules and generate exactly the manual we want. Now, with the Internet of Things and a much stronger focus on modular information, our classic manual does not seem to have a future anymore.
In a world of highly customized products, we have to deliver technical information for a particular configuration and usage scenario. With semantic software, we can provide that kind of information delivery. The software evaluates structured documentation data and delivers a dynamically assembled selection to the user.
1. New Challenges for Documentation
Technical products become more and more complex. They also come in more and more variants. According to legal requirements, each product variant needs to be shipped with matching documentation. That means that technical writers now create documentation for various product variants, different target groups, and multiple media, for example, mobile documentation for reading on a smartphone.
Also, our reading habits have changed. Rarely do we read cover-to-cover anymore. We read information in small bits. We look for the exact bit that helps us with the task that we are currently performing. We expect to find that information bit quickly and easily. We want it to fit our current scenario. We also want it to be up-to-date. We use search functions and target-group oriented filtering. We share the found information in social networks and leave a feedback.
Technical documentation for machines and devices usually describes closed technical systems with clearly defined functions and components. The documentation of a finished product also refers to a clearly defined system. In the era of the Internet of Things and cyber-physical systems whose components interact with one another, technical documentation must focus on components rather than systems. The authors need to consider how the components integrate into the system and which functions and services they provide. The documentation needs to support the operation and maintenance of components. Because the entire system is not clearly defined when a single component is produced, documentation becomes component documentation.
2. Consequences for the documentation
Our traditional, handbook-style documentation cannot cope with these challenges. Does that mean that documentation is dead? No, but the handbook style is and the way we currently deliver documentation. We will of course continue to ship products with instructions on how to operate, maintain, or repair them.
But to create target-oriented documentation in the era of the Internet of Things, technical documentation needs to further evolve.
Write modular content and classify it with metadata
Documentation that is based on components rather than entire systems needs to be modular. Many technical editing departments already write this way. They use XML architectures, such as DITA or PI-Mod, and company-specific XML architectures in content management systems. Currently, the size of documentation modules is very different. It spans from entire chapters to single sentences. A module the size of a chapter will probably not work for semantic documentation and the dynamic assembly of information bits. It has to become much smaller.
To make documentation semantic, we need metadata. Technical writers have been marking up text with metadata for some time now. They mark up text modules for specific target audiences, media, and product variants. With the Internet of Things, the component information becomes more important. Therefore, the component hierarchy needs to be included in the documentation metadata.
Modern XML content management systems already support this kind of classification. Examples are the taxonomy functions in Schema ST4 and in Docufy Cosima.
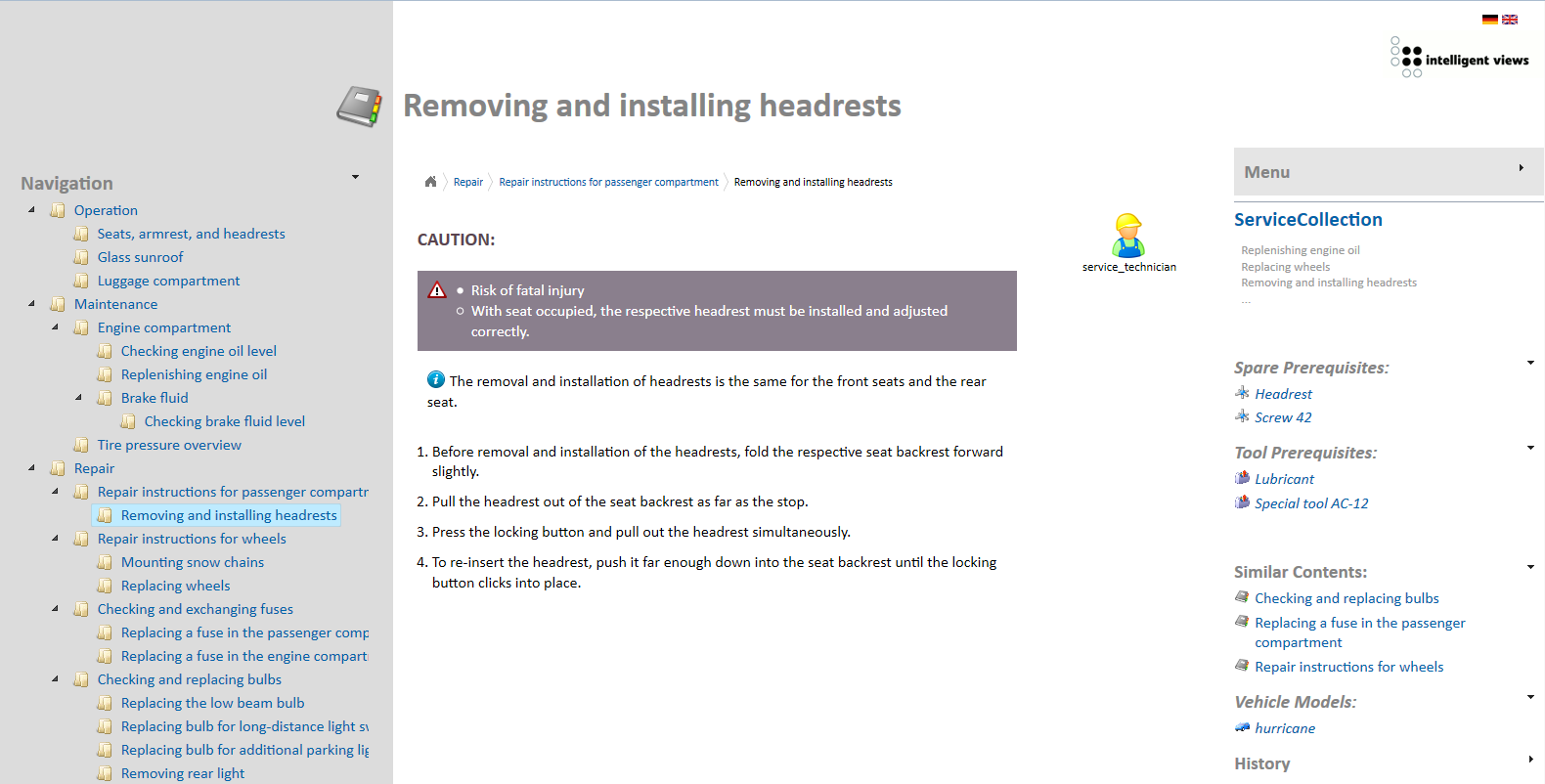
But also free XML architectures like DITA let us apply taxonomies and ontologies to technical content. The following screenshot shows a text module in oXygen (a so-called DITA topic) with metadata for the product component and information type. DITA also offers semantic elements both for machinery and plant engineering and for the software industry. That means that we can precisely query and compile content in semantic applications.
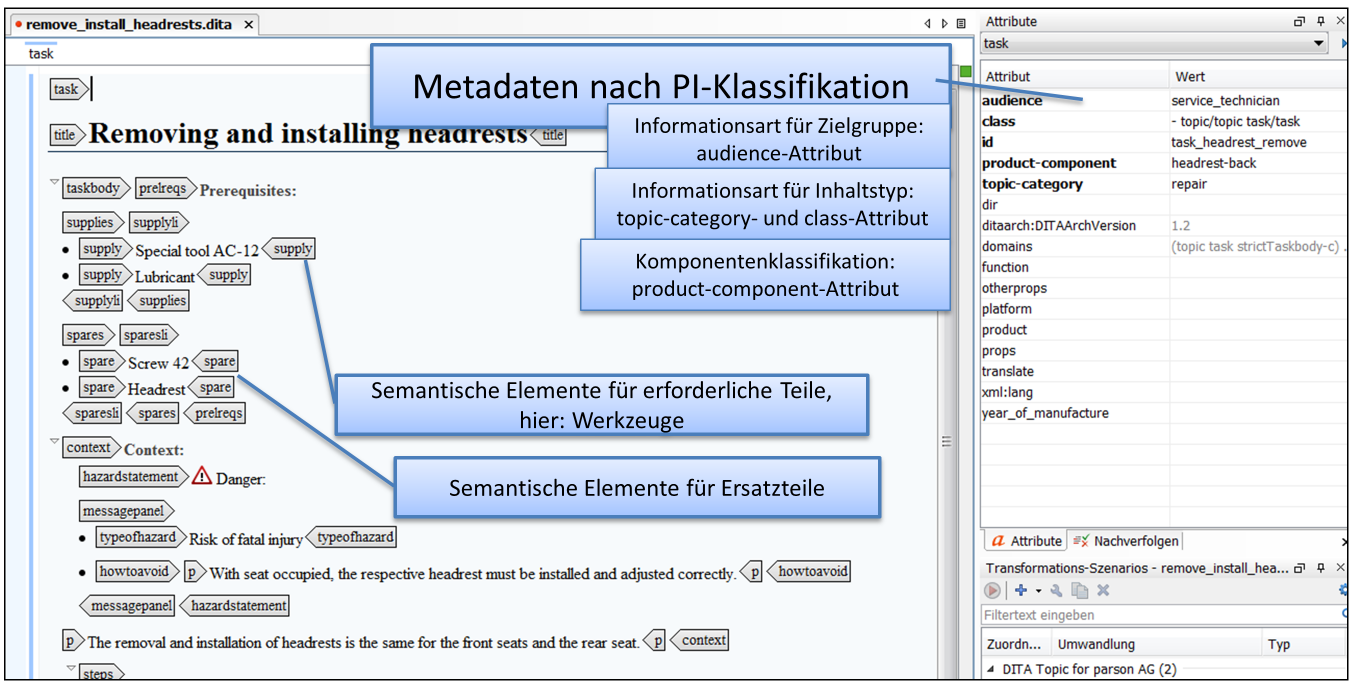
The semantic model, which serves as the basis for the classification of content, can be defined in DITA as a so-called subject-schema map. Not only does DITA offer us to build a hierarchical taxonomy, its elements also let us define the relationship between concepts.
In our screenshot example, we use, among other things, the HasPart relationship for the component taxonomy.
For defining a relationship between concepts, DITA offers classification maps and subject relationship tables. Our screenshot example shows the component-product relationship.
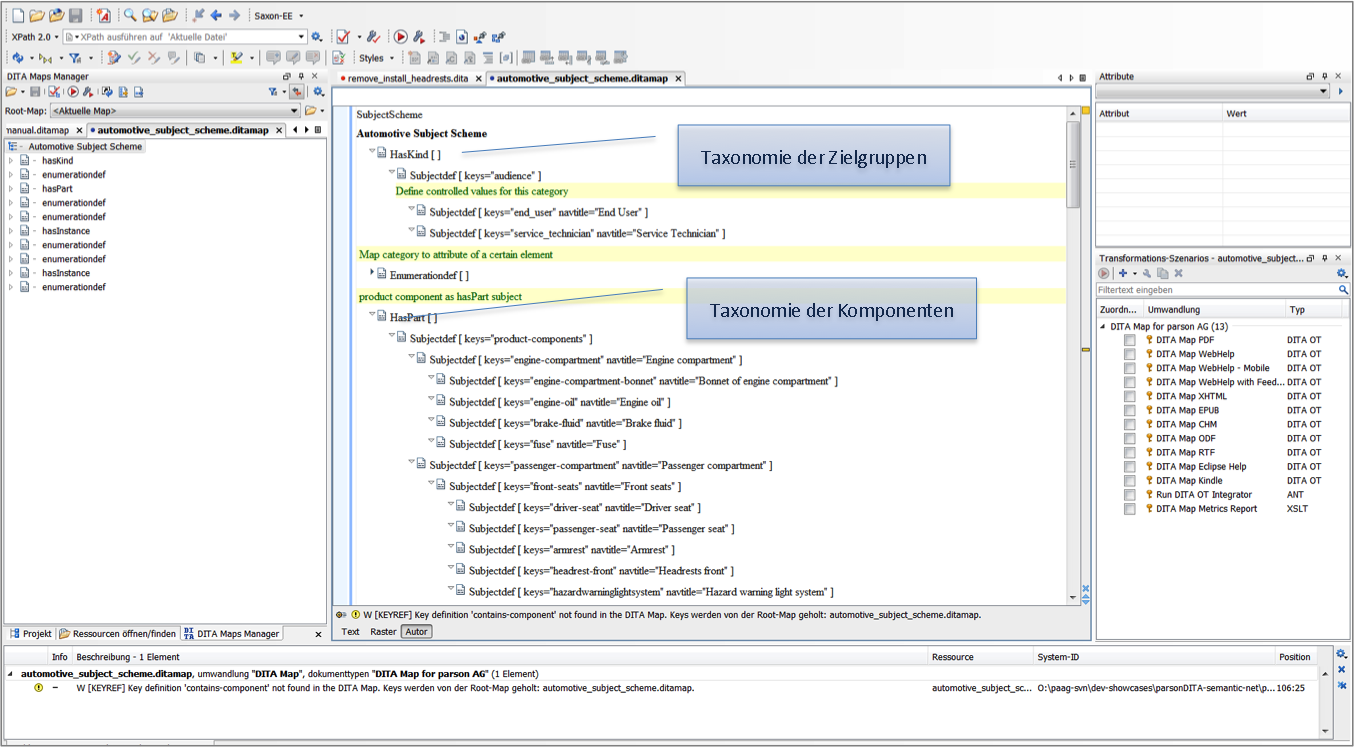
Standardize formats and terminology
As we can see from the images in the previous paragraphs, traditional technical writing tools can only handle hierarchical structures or show just one of the many possible relationships in a hierarchy at a time. They cannot manage cross-linked models (graphs). What is more, many of the entries that we use as metadata, such as the product information, are created and managed in external systems. They are not so easily available for markup. By using semantic software, we can import the metadata from external systems and integrate it. We can manage the terminology and the vocabulary. We make sure that only selected values are used to allocate the metadata, and we avoid problems that are caused by different spelling or naming conventions. By integrating the metadata, we can also connect different types of metadata with each other:
- Metadata that directly relates to certain information, such as the release status or the date of the last change, and that is directly produced in the documentation environment.
- Metadata about the information type, for example, whether the content is intended for a specific target group, or about the relationship to a (product-) component or a tool.
- Metadata for creating different product variants from components (product taxonomy).
The flexibility of semantic software also enables us to easily extend the model and to integrate content that is comes in different formats.
Images 3 and 4 show the hierarchical structure of the metadata schema and how it is actually used to describe content modules.
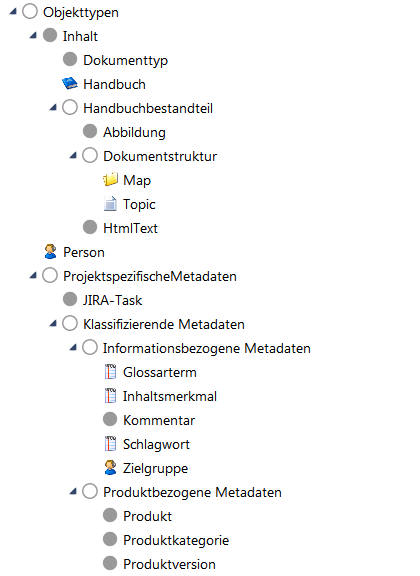
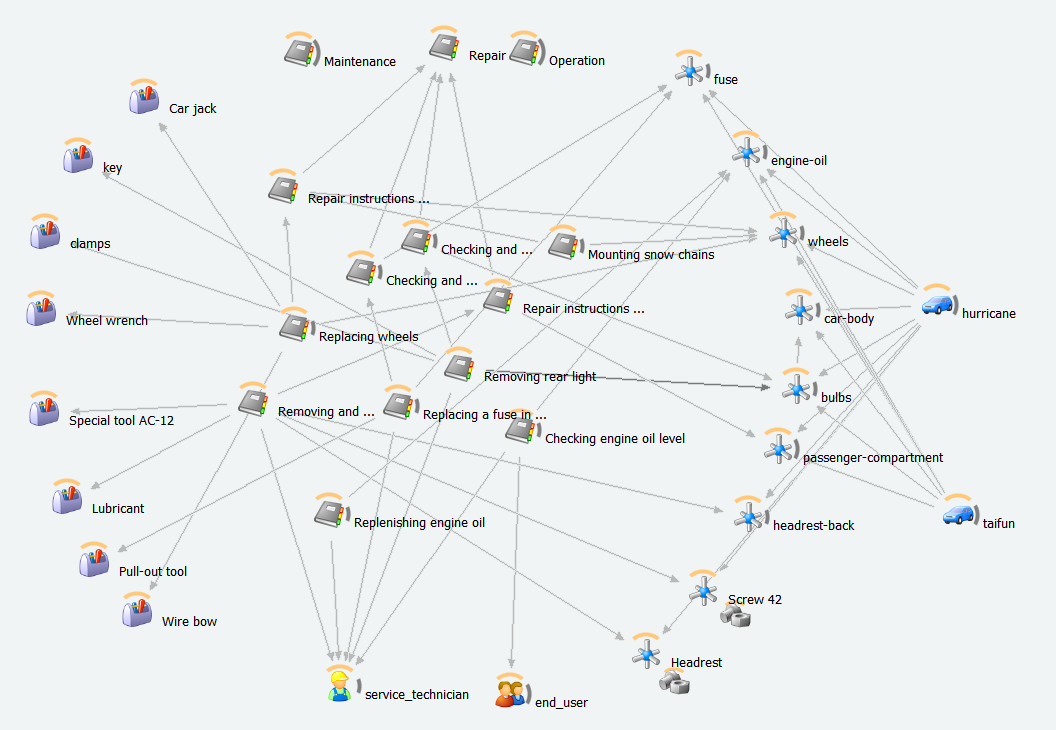
By linking content to target groups, components, and tools that originate from product information or service management systems, we can create dynamic content and publications. We can also use the metadata to provide intelligent search functions and content filters.
3. Deliver knowledge instead of documents
So far, technical writers have used metadata primarily to generate static documents. After filtering and compiling the modules, the metadata was no longer needed and therefore not part of the delivery.
This will change. Documentation created for an individualized product needs to offer dynamic assembly and content filtering. That means that we have to deliver the metadata together with the modular documentation. Only this way can users or applications search for the exact information bit that they need at the time.
Content Delivery Portals (CDPs) primarily integrate content from content management systems, but may provide standardized important interfaces, such as Docufy TopicPilot and EB.Suite. They offer a web-based interface for presenting and querying comprehensive information and documents. The content is enriched with metadata and thus can provide filters for target groups and usage scenarios, as well as semantic search queries. They do not create the content though. The content comes from one or several information management systems. CDPs are being developed by various companies or are already on the market. We distinguish between the following categories:
- CDPs that primarily integrate content from content management system. Example: Docufy TopicPilot
- Independent CDPs that integrate content that comes in a standard XML format, such as DITA. Examples of DITA CDPs are DITAweb, SuiteHelp, or Fluid Topics.
- Enterprise information portals that integrate structured and unstructured content from various systems, for example, with semantic software. One example is semantic CDP (SECONDS) by intelligent views.
Conclusion
Instead of presenting static and linear information like in the old days, we deliver information dynamically and flexibly and in different output formats. For that we need:
- a binding and across-systems classification of the documentation content,
- documentation that is delivered not only modular but also with metadata,
- technical solutions that help us present and query structured documentation in a content delivery portal or in a documentation application. Semantic technologies provide an ideal basis.